Odstranjevanje določenih znakov iz niza v programu Python
Skušam odstraniti določene znake iz niza z uporabo Pythona. To je koda, ki jo zdaj uporabljam. Na žalost se zdi, da z nizom ne naredi ničesar.
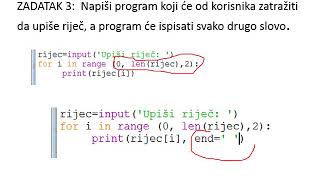
for char in line:
if char in " ?.!/;:":
line.replace(char,'')Kako naj to naredim pravilno?












Nizi v Pythonu so nepremenljivi (ni jih mogoče spremeniti). Zato je učinek line.replace(...) le ustvarjanje novega niza, ne pa spreminjanje starega. Da bi spremenljivka line prevzela novo vrednost z odstranjenimi znaki, jo morate ponovno povezati (dodeliti) spremenljivki line.
Poleg tega bo način, na katerega to počnete, precej počasen. Prav tako bo verjetno nekoliko zmedel izkušene pitonarje, ki bodo videli dvakrat vgrajeno strukturo in za trenutek pomislili, da se dogaja nekaj bolj zapletenega.
Od različice Python 2.6 in novejših različic Pythona 2.x * lahko namesto tega uporabite str.translate, (vendar si preberite še o razlikah v Pythonu 3):
line = line.translate(None, '!@#$')ali zamenjavo regularnih izrazov s re.sub
import re
line = re.sub('[!@#$]', '', line)Znaki v oklepajih predstavljajo razred znakov. Vsi znaki v line, ki spadajo v ta razred, se nadomestijo z drugim parametrom za sub: praznim nizom.
V Pythonu 3 so nizi Unicode. To omenja kevpie v komentarju k enemu od odgovorov, navedeno pa je tudi v dokumentaciji za str.translate.
Ko kličete metodo translate za niz Unicode, ne morete posredovati drugega parametra, ki smo ga uporabili zgoraj. Prav tako ne morete kot prvi parameter posredovati None ali celo tabele za prevajanje iz string.maketrans. Namesto tega morate kot edini parameter posredovati slovar. Ta slovar preslika redne vrednosti znakov (tj. rezultat klica ord zanje) v redne vrednosti znakov, ki naj bi jih nadomestili, ali - kar je za nas koristno - v None, ki označuje, da jih je treba izbrisati.
Če torej želite zgornji ples izvesti z nizom Unicode, bi morali poklicati nekaj takega, kot je
translation_table = dict.fromkeys(map(ord, '!@#$'), None)
unicode_line = unicode_line.translate(translation_table)Tu sta uporabljena dict.fromkeys in map za jedrnato ustvarjanje slovarja, ki vsebuje
{ord('!'): None, ord('@'): None, ...}Še enostavneje, kot pravi drug odgovor, je ustvariti slovar na mestu:
unicode_line = unicode_line.translate({ord(c): None for c in '!@#$'})* zaradi združljivosti s prejšnjimi Pythoni lahko ustvarite "null" prevodno tabelo, ki jo posredujete namesto None:
import string
line = line.translate(string.maketrans('', ''), '!@#$')Tukaj se string.maketrans uporablja za ustvarjanje prevajalske tabele, ki je samo niz, ki vsebuje znake z vrstnimi vrednostmi od 0 do 255.
line = line.translate(None, " ?.!/;:")Nizi so v Pythonu nespremenljivi. Metoda zamenjaj vrne nov niz po zamenjavi. Poskusite:
for char in line:
if char in " ?.!/;:":
line = line.replace(char,'')