Zeilen mit allen oder einigen NAs (fehlenden Werten) im data.frame entfernen
Ich möchte die Zeilen in diesem Datenrahmen entfernen, die:
a) in allen Spalten "N" enthalten Unten ist mein Beispiel-Datenrahmen.
gene hsap mmul mmus rnor cfam
1 ENSG00000208234 0 NA NA NA NA
2 ENSG00000199674 0 2 2 2 2
3 ENSG00000221622 0 NA NA NA NA
4 ENSG00000207604 0 NA NA 1 2
5 ENSG00000207431 0 NA NA NA NA
6 ENSG00000221312 0 1 2 3 2Grundsätzlich würde ich gerne einen Datenrahmen wie den folgenden erhalten.
gene hsap mmul mmus rnor cfam
2 ENSG00000199674 0 2 2 2 2
6 ENSG00000221312 0 1 2 3 2b) nur in einigen Spalten NA enthalten, damit ich auch dieses Ergebnis erhalten kann:
gene hsap mmul mmus rnor cfam
2 ENSG00000199674 0 2 2 2 2
4 ENSG00000207604 0 NA NA 1 2
6 ENSG00000221312 0 1 2 3 2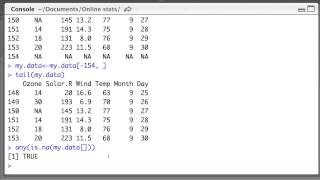










Prüfen Sie auch [complete.cases] (http://stat.ethz.ch/R-manual/R-patched/library/stats/html/complete.cases.html) :
> final[complete.cases(final), ]
gene hsap mmul mmus rnor cfam
2 ENSG00000199674 0 2 2 2 2
6 ENSG00000221312 0 1 2 3 2na.omit ist besser geeignet, um einfach alle NA's zu entfernen. complete.cases erlaubt eine teilweise Auswahl, indem nur bestimmte Spalten des Datenrahmens einbezogen werden:
> final[complete.cases(final[ , 5:6]),]
gene hsap mmul mmus rnor cfam
2 ENSG00000199674 0 2 2 2 2
4 ENSG00000207604 0 NA NA 1 2
6 ENSG00000221312 0 1 2 3 2Ihre Lösung kann nicht funktionieren. Wenn Sie darauf bestehen, is.na zu verwenden, dann müssen Sie etwas tun wie:
> final[rowSums(is.na(final[ , 5:6])) == 0, ]
gene hsap mmul mmus rnor cfam
2 ENSG00000199674 0 2 2 2 2
4 ENSG00000207604 0 NA NA 1 2
6 ENSG00000221312 0 1 2 3 2aber die Verwendung von complete.cases ist sehr viel klarer und schneller.
Versuchen Sie na.omit(your.data.frame). Versuchen Sie, die zweite Frage als weitere Frage zu stellen (der Klarheit halber).
Ich bevorzuge die folgende Methode, um zu prüfen, ob Zeilen irgendwelche NAs enthalten:
row.has.na <- apply(final, 1, function(x){any(is.na(x))})Dies gibt einen logischen Vektor mit Werten zurück, die angeben, ob eine Zeile ein NA enthält. Sie können damit feststellen, wie viele Zeilen Sie streichen müssen:
sum(row.has.na)und sie schließlich verwerfen
final.filtered <- final[!row.has.na,]Für das Filtern von Zeilen mit bestimmten Teilen von NAs wird es etwas kniffliger (zum Beispiel können Sie 'final[,5:6]' an 'apply' übergeben). Im Allgemeinen scheint die Lösung von Joris Meys eleganter zu sein.