Wie man über Zeilen in einem DataFrame in Pandas iterieren?
Ich habe ein DataFrame von Pandas:
import pandas as pd
inp = [{'c1':10, 'c2':100}, {'c1':11,'c2':110}, {'c1':12,'c2':120}]
df = pd.DataFrame(inp)
print dfAusgabe:
c1 c2
0 10 100
1 11 110
2 12 120Nun möchte ich die Zeilen dieses Rahmens durchlaufen. Für jede Zeile möchte ich in der Lage sein, auf ihre Elemente (Werte in Zellen) über den Namen der Spalten zuzugreifen. Zum Beispiel:
for row in df.rows:
print row['c1'], row['c2']Ist es möglich, dies in Pandas zu tun?
Ich habe diese ähnliche Frage gefunden. Aber es gibt mir nicht die Antwort, die ich brauche. Zum Beispiel ist es dort vorgeschlagen, zu verwenden:
for date, row in df.T.iteritems():oder
for row in df.iterrows():Aber ich verstehe nicht, was das row-Objekt ist und wie ich damit arbeiten kann.
![Pandas - Selektieren und Indexieren von Dataframes [Deutsch] | Datenanalyse mit Python](https://img.youtube.com/vi/iaziBEhdyRk/mqdefault.jpg)




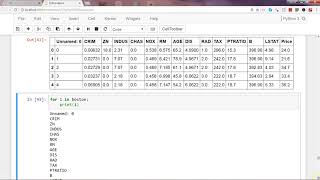







DataFrame.iterrows ist ein Generator, der sowohl Index als auch Zeile liefert
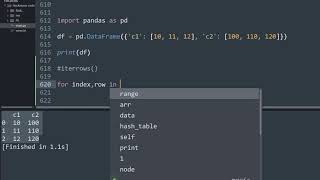
import pandas as pd
import numpy as np
df = pd.DataFrame([{'c1':10, 'c2':100}, {'c1':11,'c2':110}, {'c1':12,'c2':120}])<!- ->
for index, row in df.iterrows():
print(row['c1'], row['c2'])
Output:
10 100
11 110
12 120Sie sollten df.iterrows() verwenden. Allerdings ist die zeilenweise Aufzählung nicht besonders effizient, da Serienobjekte erstellt werden müssen.
Sie können auch df.apply() verwenden, um über Zeilen zu iterieren und auf mehrere Spalten für eine Funktion zuzugreifen.
def valuation_formula(x, y):
return x * y * 0.5
df['price'] = df.apply(lambda row: valuation_formula(row['x'], row['y']), axis=1)