Ανάλυση (διαχωρισμός) μιας συμβολοσειράς σε C++ χρησιμοποιώντας διαχωριστικό συμβολοσειράς (τυπική C++)
Αναλύω ένα αλφαριθμητικό σε C++ χρησιμοποιώντας τα ακόλουθα:
string parsed,input="text to be parsed";
stringstream input_stringstream(input);
if(getline(input_stringstream,parsed,' '))
{
// do some processing.
}Η ανάλυση με ένα μόνο διαχωριστικό char είναι μια χαρά. Τι γίνεται όμως αν θέλω να χρησιμοποιήσω ένα αλφαριθμητικό ως διαχωριστικό.
Παράδειγμα: Θέλω να χωρίσω:
scott>=tigerμε >= ως διαχωριστικό, ώστε να μπορώ να πάρω τα scott και tiger.
![What does int argc, char* argv[] mean?](https://img.youtube.com/vi/aP1ijjeZc24/mqdefault.jpg)











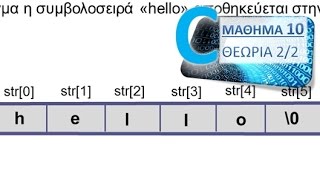

Μπορείτε να χρησιμοποιήσετε τη συνάρτηση std::string::find() για να βρείτε τη θέση του διαχωριστή της συμβολοσειράς σας και στη συνέχεια να χρησιμοποιήσετε τη συνάρτηση std::string::substr() για να λάβετε ένα token.
Παράδειγμα:
std::string s = "scott>=tiger";
std::string delimiter = ">=";
std::string token = s.substr(0, s.find(delimiter)); // token is "scott"-
Η συνάρτηση
find(const string& str, size_t pos = 0)επιστρέφει τη θέση της πρώτης εμφάνισης τουstrστο αλφαριθμητικό, ήnposαν το αλφαριθμητικό δεν έχει βρεθεί. -
Η συνάρτηση
substr(size_t pos = 0, size_t n = npos)επιστρέφει μια υποσειρά του αντικειμένου, ξεκινώντας από τη θέσηposκαι μήκουςnpos.
Αν έχετε πολλαπλούς διαχωριστές, αφού εξαγάγετε ένα σύμβολο, μπορείτε να το αφαιρέσετε (συμπεριλαμβανομένου του διαχωριστή) για να συνεχίσετε με τις επόμενες εξαγωγές (αν θέλετε να διατηρήσετε την αρχική συμβολοσειρά, απλά χρησιμοποιήστε s = s.substr(pos + delimiter.length());):
s.erase(0, s.find(delimiter) + delimiter.length());Με αυτόν τον τρόπο μπορείτε εύκολα να κάνετε βρόχο για να πάρετε κάθε συμβολικό στοιχείο.
Πλήρες παράδειγμα std::string s = "scott>=tiger>=mushroom";
std::string delimiter = ">=";
size_t pos = 0;
std::string token;
while ((pos = s.find(delimiter)) != std::string::npos) {
token = s.substr(0, pos);
std::cout << token << std::endl;
s.erase(0, pos + delimiter.length());
}
std::cout << s << std::endl;
std::string s = "scott>=tiger>=mushroom";
std::string delimiter = ">=";
size_t pos = 0;
std::string token;
while ((pos = s.find(delimiter)) != std::string::npos) {
token = s.substr(0, pos);
std::cout << token << std::endl;
s.erase(0, pos + delimiter.length());
}
std::cout << s << std::endl;Έξοδος:
scott
tiger
mushroomstrtok σας επιτρέπει να περάσετε πολλαπλά σύμβολα ως διαχωριστικά. Πάω στοίχημα ότι αν περνούσατε το ">=" η συμβολοσειρά του παραδείγματός σας θα χωριζόταν σωστά (παρόλο που τα > και = υπολογίζονται ως μεμονωμένα διαχωριστικά).
EDIT αν δεν θέλετε να χρησιμοποιήσετε την c_str() για να μετατρέψετε από συμβολοσειρά σε char*, μπορείτε να χρησιμοποιήσετε τα substr και find_first_of tokenize.
string token, mystring("scott>=tiger");
while(token != mystring){
token = mystring.substr(0,mystring.find_first_of(">="));
mystring = mystring.substr(mystring.find_first_of(">=") + 1);
printf("%s ",token.c_str());
}Θα χρησιμοποιούσα το boost::tokenizer. Εδώ'είναι η τεκμηρίωση που εξηγεί πώς να φτιάξετε μια κατάλληλη συνάρτηση tokenizer: http://www.boost.org/doc/libs/1_52_0/libs/tokenizer/tokenizerfunction.htm
Εδώ'είναι μία που λειτουργεί για την περίπτωσή σας.
struct my_tokenizer_func
{
template<typename It>
bool operator()(It& next, It end, std::string & tok)
{
if (next == end)
return false;
char const * del = ">=";
auto pos = std::search(next, end, del, del + 2);
tok.assign(next, pos);
next = pos;
if (next != end)
std::advance(next, 2);
return true;
}
void reset() {}
};
int main()
{
std::string to_be_parsed = "1) one>=2) two>=3) three>=4) four";
for (auto i : boost::tokenizer<my_tokenizer_func>(to_be_parsed))
std::cout << i << '\n';
}