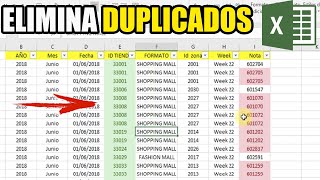
¿Cómo puedo eliminar las filas duplicadas?
¿Cuál es la mejor manera de eliminar las filas duplicadas de una tabla bastante grande de SQL Server (es decir, más de 300.000 filas)?
Las filas, por supuesto, no serán duplicados perfectos debido a la existencia del campo de identidad RowID.
MiTabla
RowID int not null identity(1,1) primary key,
Col1 varchar(20) not null,
Col2 varchar(2048) not null,
Col3 tinyint not null







Asumiendo que no hay nulos, usted Grupa por las columnas únicas, y Selecciona el MIN (o MAX) RowId como la fila a mantener. Luego, simplemente borre todo lo que no tenga un ID de fila:
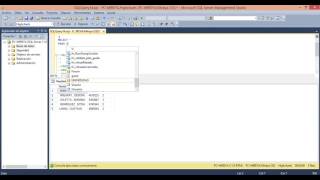
DELETE FROM MyTable
LEFT OUTER JOIN (
SELECT MIN(RowId) as RowId, Col1, Col2, Col3
FROM MyTable
GROUP BY Col1, Col2, Col3
) as KeepRows ON
MyTable.RowId = KeepRows.RowId
WHERE
KeepRows.RowId IS NULLEn caso de que tenga un GUID en lugar de un entero, puede reemplazar
MIN(RowId)por
CONVERT(uniqueidentifier, MIN(CONVERT(char(36), MyGuidColumn)))Hay un buen artículo sobre eliminar duplicados en el sitio de soporte de Microsoft. Es bastante conservador - te hacen hacer todo en pasos separados - pero debería funcionar bien contra tablas grandes.
En el pasado he utilizado autouniones para hacer esto, aunque probablemente se podría mejorar con una cláusula HAVING:
DELETE dupes
FROM MyTable dupes, MyTable fullTable
WHERE dupes.dupField = fullTable.dupField
AND dupes.secondDupField = fullTable.secondDupField
AND dupes.uniqueField > fullTable.uniqueFieldAquí hay otro buen artículo sobre la eliminación de duplicados.
Discute por qué es difícil: "SQL se basa en el álgebra relacional, y los duplicados no pueden ocurrir en el álgebra relacional, porque los duplicados no están permitidos en un conjunto."
La solución de la tabla temporal, y dos ejemplos de mysql.
En el futuro vas a prevenirlo a nivel de base de datos, o desde la perspectiva de la aplicación. Yo sugeriría el nivel de la base de datos porque su base de datos debe ser responsable de mantener la integridad referencial, los desarrolladores sólo causará problemas ;)

