Kuidas parandada: "UnicodeDecodeError: 'ascii' codec can't decode byte"
as3:~/ngokevin-site# nano content/blog/20140114_test-chinese.mkd
as3:~/ngokevin-site# wok
Traceback (most recent call last):
File "/usr/local/bin/wok", line 4, in
Engine()
File "/usr/local/lib/python2.7/site-packages/wok/engine.py", line 104, in init
self.load_pages()
File "/usr/local/lib/python2.7/site-packages/wok/engine.py", line 238, in load_pages
p = Page.from_file(os.path.join(root, f), self.options, self, renderer)
File "/usr/local/lib/python2.7/site-packages/wok/page.py", line 111, in from_file
page.meta['content'] = page.renderer.render(page.original)
File "/usr/local/lib/python2.7/site-packages/wok/renderers.py", line 46, in render
return markdown(plain, Markdown.plugins)
File "/usr/local/lib/python2.7/site-packages/markdown/init.py", line 419, in markdown
return md.convert(text)
File "/usr/local/lib/python2.7/site-packages/markdown/init.py", line 281, in convert
source = unicode(source)
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe8 in position 1: ordinal not in range(128). -- Note: Markdown only accepts unicode input!Kuidas seda parandada?
Mõnes teises pythonil põhinevas staatilises blogirakenduses saab hiina postituse edukalt avaldada. Näiteks see rakendus: http://github.com/vrypan/bucket3. Minu saidil http://bc3.brite.biz/ saab hiina keele postitust edukalt avaldada.





![[SOLVED] UnicodeEncodeError: 'charmap' codec can't encode character...](https://img.youtube.com/vi/TumTf8-wY1k/mqdefault.jpg)
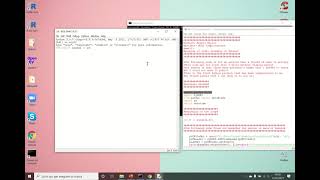



Viimselt ma sain selle:
as3:/usr/local/lib/python2.7/site-packages# cat sitecustomize.py
# encoding=utf8
import sys
reload(sys)
sys.setdefaultencoding('utf8')Lase mind kontrollida:
as3:~/ngokevin-site# python
Python 2.7.6 (default, Dec 6 2013, 14:49:02)
[GCC 4.4.5] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import sys
>>> reload(sys)
<module 'sys' (built-in)>
>>> sys.getdefaultencoding()
'utf8'
>>>Ülaltoodu näitab, et pythoni vaikimisi kodeering on utf8. Siis pole viga enam.
See on klassikaline "unicode'i probleem". Ma usun, et selle selgitamine ületab StackOverflow'i vastuse ulatust, et täielikult selgitada, mis toimub.
Seda on hästi selgitatud siin.
Väga lühidalt kokku võttes, olete edastanud midagi, mida tõlgendatakse baitide stringina, millekski, mis peab seda dekodeerima Unicode'i märkideks, kuid vaikimisi koodek (ascii) ei suuda.
Esitlus, millele ma viitasin, annab nõu, kuidas seda vältida. Tehke oma koodist "unicode sandwich". Python 2-s aitab from __future__ import unicode_literals kasutamine.
Uuendus: kuidas saab koodi parandada:
OK - teie muutuja "source" teil on mõned baidid. Sinu küsimusest ei selgu, kuidas need sinna sattusid - äkki loed neid veebivormist? Igal juhul ei ole need ascii-koodiga kodeeritud, kuid python üritab neid konverteerida unicode'iks, eeldades, et nad on seda. Sa pead talle selgesõnaliselt ütlema, milline on kodeering. See tähendab, et te peate teadma, mis on kodeering! See ei ole alati lihtne ja see sõltub täielikult sellest, kust see string pärineb. Sa võid katsetada mõne levinud kodeeringuga - näiteks UTF-8. Te ütlete unicode()-ile teise parameetrina kodeeringu:
source = unicode(source, 'utf-8')
Mõnel juhul, kui te kontrolliksite oma vaikekodeeringut (print sys.getdefaultencoding()), siis tagastab see, et te kasutate ASCII. Kui te vahetate UTF-8 vastu, siis see'ei tööta, sõltuvalt teie muutuja sisust.
Ma leidsin teise võimaluse:
import sys
reload(sys)
sys.setdefaultencoding('Cp1252')