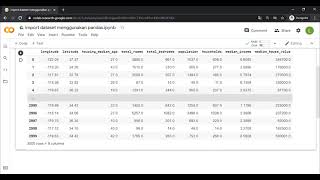
Mengimpor beberapa file csv ke panda dan menggabungkan menjadi satu DataFrame
Saya ingin membaca beberapa csv file dari suatu direktori ke panda dan menggabungkan mereka ke dalam satu besar DataFrame. Aku tidak bisa figure it out sekalipun. Berikut adalah apa yang saya miliki sejauh ini:
import glob
import pandas as pd
# get data file names
path =r'C:\DRO\DCL_rawdata_files'
filenames = glob.glob(path + "/*.csv")
dfs = []
for filename in filenames:
dfs.append(pd.read_csv(filename))
# Concatenate all data into one DataFrame
big_frame = pd.concat(dfs, ignore_index=True)Saya kira saya perlu bantuan dalam untuk loop???











Jika anda memiliki kolom yang sama di semua csv file maka anda dapat mencoba kode di bawah ini.
Saya telah menambahkan header=0 sehingga setelah membaca csv baris pertama dapat diberikan sebagai nama kolom.
import pandas as pd
import glob
path = r'C:\DRO\DCL_rawdata_files' # use your path
all_files = glob.glob(path + "/*.csv")
li = []
for filename in all_files:
df = pd.read_csv(filename, index_col=None, header=0)
li.append(df)
frame = pd.concat(li, axis=0, ignore_index=True)Alternatif untuk darindaCoder's jawaban:
path = r'C:\DRO\DCL_rawdata_files' # use your path
all_files = glob.glob(os.path.join(path, "*.csv")) # advisable to use os.path.join as this makes concatenation OS independent
df_from_each_file = (pd.read_csv(f) for f in all_files)
concatenated_df = pd.concat(df_from_each_file, ignore_index=True)
# doesn't create a list, nor does it append to oneimport glob, os
df = pd.concat(map(pd.read_csv, glob.glob(os.path.join('', "my_files*.csv"))))Yang Cmintalah perpustakaan dapat membaca dataframe dari beberapa file:
>>> impor cmintalah.dataframe sebagai dd
>>> df = dd.read_csv('data*.csv')
(Sumber: http://dask.pydata.org/en/latest/examples/dataframe-csv.html)
Yang Cmintalah dataframes mengimplementasikan subset dari Panda dataframe API. Jika semua sesuai dengan data ke dalam memori, anda dapat panggilan df.menghitung() untuk mengkonversi dataframe ke Panda dataframe.
Hampir semua jawaban di sini adalah baik tidak perlu kompleks (glob pencocokan pola) atau mengandalkan tambahan perpustakaan pihak ke-3. Anda dapat melakukan ini dalam 2 baris menggunakan segala sesuatu Panda dan python (semua versi) sudah memiliki built in.
Untuk beberapa file - 1 kapal:
df = pd.concat(map(pd.read_csv, ['data/d1.csv', 'data/d2.csv','data/d3.csv']))Untuk banyak file:
from os import listdir
filepaths = [f for f in listdir("./data") if f.endswith('.csv')]
df = pd.concat(map(pd.read_csv, filepaths))Ini panda garis yang menetapkan df menggunakan 3 hal:
- Python's peta (fungsi, iterable) mengirimkan ke fungsi (
pd.read_csv()) yang iterable (daftar) yang lebih csv setiap elemen di filepaths). - Panda's read_csv() fungsi membaca dalam masing-masing CSV file seperti biasa.
- Panda's concat() membawa semua ini di bawah satu variabel df.
Edit: saya googled jalan saya ke https://stackoverflow.com/a/21232849/186078. Namun akhir-akhir ini saya menemukan itu lebih cepat untuk melakukan manipulasi menggunakan numpy, dan kemudian menugaskan sekali untuk dataframe daripada memanipulasi dataframe sendiri pada iteratif dasar dan tampaknya untuk bekerja di solusi ini juga.
Saya sungguh-sungguh ingin siapa pun memukul halaman ini untuk mempertimbangkan pendekatan ini, tapi don't ingin melampirkan sepotong besar kode sebagai komentar dan membuatnya lebih mudah dibaca.
Anda dapat memanfaatkan numpy untuk benar-benar mempercepat dataframe rangkaian.
import os
import glob
import pandas as pd
import numpy as np
path = "my_dir_full_path"
allFiles = glob.glob(os.path.join(path,"*.csv"))
np_array_list = []
for file_ in allFiles:
df = pd.read_csv(file_,index_col=None, header=0)
np_array_list.append(df.as_matrix())
comb_np_array = np.vstack(np_array_list)
big_frame = pd.DataFrame(comb_np_array)
big_frame.columns = ["col1","col2"....]Waktu stats:
total files :192
avg lines per file :8492
--approach 1 without numpy -- 8.248656988143921 seconds ---
total records old :1630571
--approach 2 with numpy -- 2.289292573928833 seconds ---Jika anda ingin pencarian rekursif (Python 3.5 atau above), anda dapat melakukan hal-hal berikut:
from glob import iglob
import pandas as pd
path = r'C:\user\your\path\**\*.csv'
all_rec = iglob(path, recursive=True)
dataframes = (pd.read_csv(f) for f in all_rec)
big_dataframe = pd.concat(dataframes, ignore_index=True)Perhatikan bahwa tiga baris terakhir dapat dinyatakan dalam satu satu baris:
df = pd.concat((pd.read_csv(f) for f in iglob(path, recursive=True)), ignore_index=True)Anda dapat menemukan dokumentasi dari ** di sini. Juga, saya menggunakan iglob'instead daridunia`, karena itu kembali iterator bukan daftar.
EDIT: Multiplatform fungsi rekursif:
Anda dapat membungkus di atas ke multiplatform fungsi (Linux, Windows, Mac), sehingga anda dapat melakukan:
df = read_df_rec('C:\user\your\path', *.csv)Berikut ini adalah fungsi:
from glob import iglob
from os.path import join
import pandas as pd
def read_df_rec(path, fn_regex=r'*.csv'):
return pd.concat((pd.read_csv(f) for f in iglob(
join(path, '**', fn_regex), recursive=True)), ignore_index=True)salah satu kapal menggunakan peta, tetapi jika anda'd seperti untuk menentukan tambahan args, anda bisa melakukan:
``python impor panda sebagai pd impor glob impor functools
df = pd.concat(peta(functools.parsial(pd.read_csv, sep='|', kompresi=Tidak ada), glob.glob("data/*.csv"))) ``
Catatan: peta dengan sendirinya tidak membiarkan anda pasokan tambahan args.
Jika beberapa csv file zip, anda dapat menggunakan zipfile untuk membaca semua dan menggabungkan seperti di bawah ini:
import zipfile
import numpy as np
import pandas as pd
ziptrain = zipfile.ZipFile('yourpath/yourfile.zip')
train=[]
for f in range(0,len(ziptrain.namelist())):
if (f == 0):
train = pd.read_csv(ziptrain.open(ziptrain.namelist()[f]))
else:
my_df = pd.read_csv(ziptrain.open(ziptrain.namelist()[f]))
train = (pd.DataFrame(np.concatenate((train,my_df),axis=0),
columns=list(my_df.columns.values)))Mudah dan Cepat
Impor dua atau lebih csv's tanpa harus membuat daftar nama.
`` impor glob
df = pd.concat(peta(pd.read_csv, glob.glob('data/*.csv'))) ``
Saya menemukan metode ini cukup elegan.
import pandas as pd
import os
big_frame = pd.DataFrame()
for file in os.listdir():
if file.endswith('.csv'):
df = pd.read_csv(file)
big_frame = big_frame.append(df, ignore_index=True)Berdasarkan @Sid's jawaban yang baik.
Sebelum concatenating, anda dapat memuat file csv menjadi perantara kamus yang memberikan akses untuk masing-masing set data berdasarkan nama file (dalam bentuk dict_of_df['filename.csv']). Seperti sebuah kamus yang dapat membantu anda mengidentifikasi masalah yang heterogen dengan format data, ketika nama-nama kolom yang tidak selaras misalnya.
Import modul dan cari file path:
import os
import glob
import pandas
from collections import OrderedDict
path =r'C:\DRO\DCL_rawdata_files'
filenames = glob.glob(path + "/*.csv")Catatan: OrderedDict tidak perlu,
tapi itu'll menjaga agar file-file yang mungkin berguna untuk analisis.
Load csv file ke dalam kamus. Kemudian concatenate:
dict_of_df = OrderedDict((f, pandas.read_csv(f)) for f in filenames)
pandas.concat(dict_of_df, sort=True)Kunci nama file f dan nilai-nilai data frame isi dari file csv.
Alih-alih menggunakan f sebagai kamus kunci, anda juga dapat menggunakan os.jalan.basename(f) atau lainnya os.path metode untuk mengurangi ukuran kunci dalam kamus-satunya bagian yang lebih kecil yang lebih relevan.
Alternatif menggunakan pathlib perpustakaan (sering lebih disukai os.path).
Metode ini menghindari iteratif menggunakan panda concat()/apped().
Dari panda dokumentasi:
Perlu dicatat bahwa concat() (dan oleh karena itu append()) membuat salinan lengkap dari data, dan yang terus-menerus menggunakan fungsi ini dapat membuat kinerja yang signifikan memukul. Jika anda perlu untuk menggunakan operasi selama beberapa dataset, menggunakan daftar pemahaman.
`` impor panda sebagai pd dari pathlib impor Jalan
dir = Path("../relevant_directory")
df = (pd.read_csv(f) untuk f di dir.glob("*.csv")) df = pd.concat(df) ``





