Gunakan .corr untuk mendapatkan korelasi antara dua kolom
Saya memiliki berikut panda dataframe Top15:

Saya membuat sebuah kolom yang memperkirakan jumlah citable dokumen per orang:
Top15['PopEst'] = Top15['Energy Supply'] / Top15['Energy Supply per Capita']
Top15['Citable docs per Capita'] = Top15['Citable documents'] / Top15['PopEst']Saya ingin mengetahui hubungan antara jumlah citable dokumen per kapita dan pasokan energi per kapita. Jadi saya gunakan .corr() metode (Pearson's korelasi):
data = Top15[['Citable docs per Capita','Energy Supply per Capita']]
correlation = data.corr(method='pearson')Aku ingin kembali nomor tunggal, tapi hasilnya adalah:




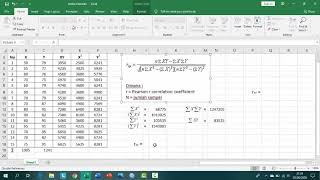
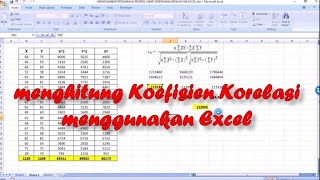
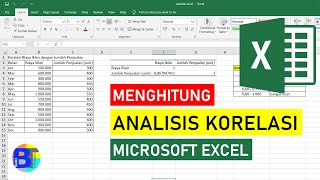
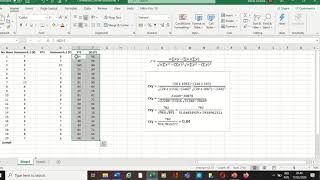



Tanpa data yang sebenarnya sulit untuk menjawab pertanyaan tetapi saya kira anda sedang mencari sesuatu seperti ini:
Top15['Citable docs per Capita'].corr(Top15['Energy Supply per Capita'])Yang menghitung korelasi antara dua kolom 'Citable docs per Kapita' dan 'Pasokan Energi per Kapita'.
Untuk memberikan sebuah contoh:
import pandas as pd
df = pd.DataFrame({'A': range(4), 'B': [2*i for i in range(4)]})
A B
0 0 0
1 1 2
2 2 4
3 3 6Kemudian
df['A'].corr(df['B'])memberikan 1 seperti yang diharapkan.
Sekarang, jika anda mengubah value, misalnya
df.loc[2, 'B'] = 4.5
A B
0 0 0.0
1 1 2.0
2 2 4.5
3 3 6.0perintah
df['A'].corr(df['B'])kembali
0.99586yang masih dekat dengan 1, seperti yang diharapkan.
Jika anda menerapkan .corr langsung ke dataframe, itu akan mengembalikan semua berpasangan korelasi antara kolom; yang's mengapa anda kemudian mengamati 1 pada diagonal dari matriks (masing-masing kolom adalah sangat berkorelasi dengan dirinya sendiri).
df.corr()oleh karena itu akan kembali
A B
A 1.000000 0.995862
B 0.995862 1.000000Dalam grafis yang anda lihat, hanya sudut kiri atas dari matriks korelasi diwakili (saya asumsikan).
Bisa ada kasus, di mana anda mendapatkan `NaN dalam solusi anda - check post ini untuk contoh.
Jika anda ingin untuk menyaring entri di atas/di bawah ambang batas tertentu, anda dapat memeriksa pertanyaan. Jika anda ingin plot heatmap dari koefisien korelasi, anda dapat memeriksa ini answer dan jika anda kemudian lari ke masalah tumpang tindih dengan sumbu-label check berikut post.
Aku berlari ke dalam masalah yang sama.
Ternyata Citable Dokumen per Orang adalah float, dan python melompat entah bagaimana secara default. Semua kolom lainnya saya dataframe yang di numpy-format, jadi saya dipecahkan dengan mengubah columnt untuk np.float64
Top15['Citable Documents per Person']=np.float64(Top15['Citable Documents per Person'])Ingat itu's persis kolom anda dihitung sendiri
Solusi saya akan setelah konversi data ke tipe numerik:
Top15[['Citable docs per Capita','Energy Supply per Capita']].corr()Ketika anda menelepon ini:
data = Top15[['Citable docs per Capita','Energy Supply per Capita']]
correlation = data.corr(method='pearson')Karena, DataFrame.corr() fungsi melakukan pair-wise korelasi, anda memiliki empat pasangan dari dua variabel. Jadi, pada dasarnya anda mendapatkan diagonal nilai-nilai sebagai auto korelasi (korelasi dengan dirinya sendiri, dua nilai karena anda memiliki dua variabel), dan dua lainnya nilai-nilai sebagai cross korelasi dari satu lebih baik dari yang lain dan sebaliknya.
Baik melakukan korelasi antara dua seri untuk mendapatkan nilai tunggal:
from scipy.stats.stats import pearsonr
docs_col = Top15['Citable docs per Capita'].values
energy_col = Top15['Energy Supply per Capita'].values
corr , _ = pearsonr(docs_col, energy_col)atau, jika anda ingin satu nilai dari fungsi yang sama (DataFrame's corr):
single_value = correlation[0][1] Semoga ini bisa membantu.
Ia bekerja seperti ini:
Top15['Citable docs per Capita']=np.float64(Top15['Citable docs per Capita'])
Top15['Energy Supply per Capita']=np.float64(Top15['Energy Supply per Capita'])
Top15['Energy Supply per Capita'].corr(Top15['Citable docs per Capita'])Jika anda ingin korelasi antara semua pasangan dari kolom, anda bisa melakukan sesuatu seperti ini:
import pandas as pd
import numpy as np
def get_corrs(df):
col_correlations = df.corr()
col_correlations.loc[:, :] = np.tril(col_correlations, k=-1)
cor_pairs = col_correlations.stack()
return cor_pairs.to_dict()
my_corrs = get_corrs(df)
# and the following line to retrieve the single correlation
print(my_corrs[('Citable docs per Capita','Energy Supply per Capita')])Saya memecahkan masalah ini dengan mengubah tipe data. Jika anda melihat 'Pasokan Energi per Kapita' adalah tipe numerik sementara 'Citable docs per Kapita' adalah jenis objek. Saya masuk kolom untuk mengapung menggunakan astype. Aku punya masalah yang sama dengan beberapa np fungsi: count_nonzero dan jumlah bekerja sementara berarti dan std didn't.





