Altro
Question
Come cambiare l'ordine delle colonne del DataFrame?
Ho il seguente DataFrame (df):
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.rand(10, 5))Aggiungo altre colonne per assegnazione:
df['mean'] = df.mean(1)Come posso spostare la colonna mean davanti, cioè impostarla come prima colonna lasciando intatto l'ordine delle altre colonne?
718
3
Popular videos


4 anni fa






5 anni fa


Questa domanda ha 1 rispondere in inglese, per leggerle accedi al tuo account.
Un modo semplice sarebbe quello di riassegnare il dataframe con una lista di colonne, riordinate come necessario.
Questo è quello che hai ora:
In [6]: df
Out[6]:
0 1 2 3 4 mean
0 0.445598 0.173835 0.343415 0.682252 0.582616 0.445543
1 0.881592 0.696942 0.702232 0.696724 0.373551 0.670208
2 0.662527 0.955193 0.131016 0.609548 0.804694 0.632596
3 0.260919 0.783467 0.593433 0.033426 0.512019 0.436653
4 0.131842 0.799367 0.182828 0.683330 0.019485 0.363371
5 0.498784 0.873495 0.383811 0.699289 0.480447 0.587165
6 0.388771 0.395757 0.745237 0.628406 0.784473 0.588529
7 0.147986 0.459451 0.310961 0.706435 0.100914 0.345149
8 0.394947 0.863494 0.585030 0.565944 0.356561 0.553195
9 0.689260 0.865243 0.136481 0.386582 0.730399 0.561593
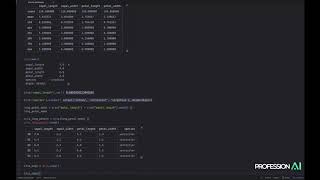
In [7]: cols = df.columns.tolist()
In [8]: cols
Out[8]: [0L, 1L, 2L, 3L, 4L, 'mean']Riorganizza i cols in qualsiasi modo tu voglia. Ecco come ho spostato l'ultimo elemento nella prima posizione:
In [12]: cols = cols[-1:] + cols[:-1]
In [13]: cols
Out[13]: ['mean', 0L, 1L, 2L, 3L, 4L]Poi riordina il dataframe in questo modo:
In [16]: df = df[cols] # OR df = df.ix[:, cols]
In [17]: df
Out[17]:
mean 0 1 2 3 4
0 0.445543 0.445598 0.173835 0.343415 0.682252 0.582616
1 0.670208 0.881592 0.696942 0.702232 0.696724 0.373551
2 0.632596 0.662527 0.955193 0.131016 0.609548 0.804694
3 0.436653 0.260919 0.783467 0.593433 0.033426 0.512019
4 0.363371 0.131842 0.799367 0.182828 0.683330 0.019485
5 0.587165 0.498784 0.873495 0.383811 0.699289 0.480447
6 0.588529 0.388771 0.395757 0.745237 0.628406 0.784473
7 0.345149 0.147986 0.459451 0.310961 0.706435 0.100914
8 0.553195 0.394947 0.863494 0.585030 0.565944 0.356561
9 0.561593 0.689260 0.865243 0.136481 0.386582 0.730399Che ne dici di:
df.insert(0, 'mean', df.mean(1))http://pandas.pydata.org/pandas-docs/stable/dsintro.html#column-selection-addition-deletion
Comunità collegate
2


Python Data Science
67 utenti