Pandasでカラムのデータ型を変更する
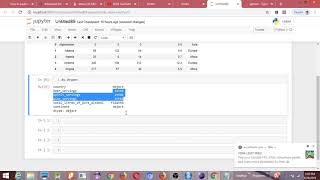
リストのリストとして表現されるテーブルを、Pandas DataFrameに変換したい。極端に簡略化した例として
a = [['a', '1.2', '4.2'], ['b', '70', '0.03'], ['x', '5', '0']]
df = pd.DataFrame(a)列を適切な型に変換する最良の方法は何でしょうか。この場合、列2と3はfloatに変換します。DataFrameに変換する際に、型を指定する方法はありますか?それとも、最初にDataFrameを作成し、その後、列をループして各列の型を変更するのが良いのでしょうか?理想的には、数百のカラムがあり、どのカラムがどのタイプであるかを正確に指定したくないので、動的な方法でこれを行いたいと考えています。私が保証できるのは、各カラムが同じ型の値を含むことだけです。













pandasで型を変換するには、主に3つのオプションがあります:
1.1. to_numeric() - 非数値型 (文字列など) を適切な数値型に安全に変換する機能を提供します。(to_datetime()](http://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.to_datetime.html#pandas.to_datetime) と to_timedelta() も参照してください)。
2.astype()` - (ほとんど)あらゆる型を(ほとんど)他の型に変換します(たとえそうすることが必ずしも賢明でないとしても)。また、categorial型への変換も可能です(非常に便利です)。
3.3. infer_objects() - Pythonオブジェクトを保持するオブジェクトカラムを、可能であればpandas型に変換するユーティリティメソッドです。
各メソッドの詳細な説明と使用方法については、こちらをご覧ください。
1.to_numeric()
DataFrameの1つまたは複数のカラムを数値に変換するには、pandas.to_numeric()を使用するのが一番よい方法です。
この関数は、数値以外のオブジェクト(文字列など)を、適宜、整数や浮動小数点数などに変換しようとします。
基本的な使い方
to_numeric()`の入力は、SeriesまたはDataFrameの1カラムである。
>>> s = pd.Series(["8", 6, "7.5", 3, "0.9"]) # mixed string and numeric values
>>> s
0 8
1 6
2 7.5
3 3
4 0.9
dtype: object
>>> pd.to_numeric(s) # convert everything to float values
0 8.0
1 6.0
2 7.5
3 3.0
4 0.9
dtype: float64ご覧のように、新しいSeriesが返されます。この出力を継続して使用するには、変数またはカラム名に割り当てることを忘れないでください:
# convert Series
my_series = pd.to_numeric(my_series)
# convert column "a" of a DataFrame
df["a"] = pd.to_numeric(df["a"])また、apply()メソッドでDataFrameの複数のカラムを変換することも可能です:
# convert all columns of DataFrame
df = df.apply(pd.to_numeric) # convert all columns of DataFrame
# convert just columns "a" and "b"
df[["a", "b"]] = df[["a", "b"]].apply(pd.to_numeric)値がすべて変換できるのであれば、それだけで十分でしょう。
エラー処理
しかし、ある値が数値型に変換できない場合はどうすればよいでしょうか。
to_numeric()はerrorsキーワード引数を取り、数値以外の値を強制的にNaNにしたり、これらの値を含むカラムを単に無視したりすることができます。 以下は、オブジェクトのd型を持つ文字列の系列s` を使った例である:
>>> s = pd.Series(['1', '2', '4.7', 'pandas', '10'])
>>> s
0 1
1 2
2 4.7
3 pandas
4 10
dtype: objectデフォルトの動作は、値を変換できない場合に発生するものです。この場合、文字列 'pandas' に対処できない:
>>> pd.to_numeric(s) # or pd.to_numeric(s, errors='raise')
ValueError: Unable to parse string失敗するのではなく、 'pandas' が欠落している/悪い数値とみなされることを望むかもしれません。キーワード引数 errors を使って、以下のように無効な値を NaN に強制的に変換することができます:
>>> pd.to_numeric(s, errors='coerce')
0 1.0
1 2.0
2 4.7
3 NaN
4 10.0
dtype: float64errors`の3番目のオプションは、無効な値に遭遇した場合に操作を無視することだけです:
>>> pd.to_numeric(s, errors='ignore')
# the original Series is returned untouchedこの最後のオプションは、DataFrame全体を変換したいが、どのカラムが確実に数値型に変換できるのか分からない場合に特に有効です。その場合は、次のように書けばよい:
df.apply(pd.to_numeric, errors='ignore')関数は、DataFrameの各カラムに適用されます。数値型に変換できるカラムは変換され、変換できないカラム(例えば、非桁の文字列や日付を含む)はそのまま残されます。
ダウンキャスト
デフォルトでは、to_numeric()による変換は int64 または float64 のいずれかの dtype を与えます(あるいは、あなたのプラットフォームのネイティブな整数幅を使用します)。
しかし、メモリを節約して float32 や int8 のようなコンパクトなデータ型を使いたい場合はどうすればよいでしょうか。
to_numeric()では、 'integer', 'signed', 'unsigned', 'float' のいずれかにダウンキャストするオプションを提供します。以下は、整数型の単純な系列s` の例である:
>>> s = pd.Series([1, 2, -7])
>>> s
0 1
1 2
2 -7
dtype: int64へのダウンキャストは、値を保持できる最小の整数を使用します:
>>> pd.to_numeric(s, downcast='integer')
0 1
1 2
2 -7
dtype: int8ダウンキャストで 'float' も同様に、通常より小さい浮遊型を選びます:
>>> pd.to_numeric(s, downcast='float')
0 1.0
1 2.0
2 -7.0
dtype: float322.アスティペ()`
astype()`](https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.astype.html)メソッドは、DataFrameやSeriesに持たせたいdtypeを明示的に指定することができます。このメソッドは、あるデータ型から他のデータ型への移行を試みることができるという点で、非常に汎用的です。
基本的な使い方
NumPyの型(例えば np.int16), Pythonの型(例えば bool), pandas特有の型(categorical dtypeなど)を使用することができます。
変換したいオブジェクトのメソッドを呼び出すと、astype()が変換を試みてくれます:
# convert all DataFrame columns to the int64 dtype
df = df.astype(int)
# convert column "a" to int64 dtype and "b" to complex type
df = df.astype({"a": int, "b": complex})
# convert Series to float16 type
s = s.astype(np.float16)
# convert Series to Python strings
s = s.astype(str)
# convert Series to categorical type - see docs for more details
s = s.astype('category')もし astype() がシリーズやデータフレーム内の値の変換方法を知らない場合、エラーを発生させます。例えば、NaNやinfの値がある場合、それを整数に変換しようとするとエラーになります。
pandas 0.20.0 では、このエラーは errors='ignore' を渡すことで抑制することができます。元のオブジェクトはそのまま返されます。
注意すること
astype()`は強力ですが、時に値を不正に変換してしまうことがあります。例えば、以下のような感じです:
>>> s = pd.Series([1, 2, -7])
>>> s
0 1
1 2
2 -7
dtype: int64これらは小さな整数なので、メモリを節約するために符号なし8ビット型に変換してはどうでしょうか。
>>> s.astype(np.uint8)
0 1
1 2
2 249
dtype: uint8変換はうまくいったのですが、-7が回り込んで249になってしまいました(つまり、28 - 7)!
代わりに pd.to_numeric(s, downcast='unsigned') を使ってダウンキャストしてみると、このエラーを防ぐことができるかもしれません。
3.infer_objects() を実行する。
pandasのバージョン0.21.0では、DataFrameのobjectデータ型を持つカラムをより特定の型に変換する(ソフトコンバージョン)ためのメソッド infer_objects() を導入しました。
例えば、ここにオブジェクト型の2つのカラムを持つDataFrameがあります。一方は実際の整数を保持し、もう一方は整数を表す文字列を保持します:
>>> df = pd.DataFrame({'a': [7, 1, 5], 'b': ['3','2','1']}, dtype='object')
>>> df.dtypes
a object
b object
dtype: objectinfer_objects()`を使うと、カラム 'a' の型をint64に変更することができます:
>>> df = df.infer_objects()
>>> df.dtypes
a int64
b object
dtype: objectカラム 'b' は、その値が整数ではなく文字列であったため、そのままにしてあります。もし、両方のカラムを強制的に整数型に変換しようと思ったら、代わりに df.astype(int) を使うことができます。
こんなのはどうでしょう。
a = [['a', '1.2', '4.2'], ['b', '70', '0.03'], ['x', '5', '0']]
df = pd.DataFrame(a, columns=['one', 'two', 'three'])
df
Out[16]:
one two three
0 a 1.2 4.2
1 b 70 0.03
2 x 5 0
df.dtypes
Out[17]:
one object
two object
three object
df[['two', 'three']] = df[['two', 'three']].astype(float)
df.dtypes
Out[19]:
one object
two float64
three float64この下のコードは、列のデータ型を変更します。
df[['col.name1', 'col.name2'...]] = df[['col.name1', 'col.name2'..]].astype('data_type')データタイプの代わりに、データ型を指定できます。str、float、intなど、何が欲しいですか。
DataFrameと列のリストを引数にとり、列のデータをすべて数値に変換する関数を紹介します。
# df is the DataFrame, and column_list is a list of columns as strings (e.g ["col1","col2","col3"])
# dependencies: pandas
def coerce_df_columns_to_numeric(df, column_list):
df[column_list] = df[column_list].apply(pd.to_numeric, errors='coerce')では、例の件ですが:
import pandas as pd
def coerce_df_columns_to_numeric(df, column_list):
df[column_list] = df[column_list].apply(pd.to_numeric, errors='coerce')
a = [['a', '1.2', '4.2'], ['b', '70', '0.03'], ['x', '5', '0']]
df = pd.DataFrame(a, columns=['col1','col2','col3'])
coerce_df_columns_to_numeric(df, ['col2','col3'])特定の列を指定するだけで、明示的にしたい場合は、(DOCS LOCATIONあたり)を使用しました。
dataframe = dataframe.astype({'col_name_1':'int','col_name_2':'float64', etc. ...})したがって、元の質問を使用しますが、列名を提供します。 ...
a = [['a', '1.2', '4.2'], ['b', '70', '0.03'], ['x', '5', '0']]
df = pd.DataFrame(a, columns=['col_name_1', 'col_name_2', 'col_name_3'])
df = df.astype({'col_name_2':'float64', 'col_name_3':'float64'})2つのデータフレームを作成して、それぞれ列に異なるデータタイプを作成し、それらを一緒に追加するのはどうですか?
d1 = pd.DataFrame(columns=[ 'float_column' ], dtype=float)
d1 = d1.append(pd.DataFrame(columns=[ 'string_column' ], dtype=str))結果。
In[8}: d1.dtypes
Out[8]:
float_column float64
string_column object
dtype: objectデータフレームが作成されたら、最初の列に浮動小数点変数、2番目の列に文字列(または必要なデータ型)を入力できます。
同じ問題があると思いましたが、実際には少し違いがあり、問題の解決が容易になります。 この質問を見る他の人にとっては、入力リストの形式を確認する価値があります。 私の場合、数値は質問のように最初は文字列ではなく浮動小数点です。
a = [['a', 1.2, 4.2], ['b', 70, 0.03], ['x', 5, 0]]しかし、データフレームを作成する前にリストを処理しすぎると、タイプが失われ、すべてが文字列になります。
numpy配列を介してデータフレームを作成します。
``。 df = pd.DataFrame(np.array(a))。
df。 アウト[5]: 0 1 2。 0 a 1.2 4.2。 1 b 70 0.03。 2 x 5 0。
df [1] .dtype。 Out [7]:dtype( 'O')。 ``。
質問と同じデータフレームを提供します。列1と2のエントリは文字列と見なされます。 しかし、やっています。 ``。 df = pd.DataFrame(a)。
df。 アウト[10]: 0 1 2。 0 a 1.2 4.20。 1 b 70.0 0.03。 2 x 5.0 0.00。
df [1] .dtype。 アウト[11]:dtype( 'float64')。 ``。 実際には、正しい形式の列を持つデータフレームが表示されます。