Diferença entre escalonamento horizontal e vertical para bases de dados
Já me deparei com muitos bancos de dados NoSQL e bancos de dados SQL. Existem vários parâmetros para medir a força e os pontos fracos destes bancos de dados e a escalabilidade é um deles. Qual é a diferença entre escalar horizontalmente e verticalmente estes bancos de dados?

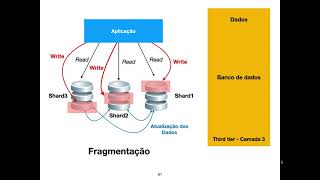











Escalação horizontal significa que você escalona adicionando mais máquinas ao seu pool de recursos, enquanto **escalação vertical significa que você escala adicionando mais energia (CPU, RAM) a uma máquina existente***.
Uma maneira fácil de lembrar isto é pensar em uma máquina em um rack de servidor, nós adicionamos mais máquinas na direção horizontal e adicionamos mais recursos a uma máquina na direção **vertical***.

Em um mundo de banco de dados o dimensionamento horizontal é frequentemente baseado no particionamento dos dados, ou seja, cada nó contém apenas parte dos dados, em dimensionamento vertical os dados residem em um único nó e o dimensionamento é feito através de múltiplos núcleos, ou seja, espalhando a carga entre a CPU e os recursos de RAM daquela máquina.
Com a escala horizontal é muitas vezes mais fácil escalar dinamicamente adicionando mais máquinas à piscina existente - A escala vertical é muitas vezes limitada à capacidade de uma única máquina, escalar para além dessa capacidade envolve frequentemente tempo de paragem e vem com um limite superior.
Bons exemplos de dimensionamento horizontal são Cassandra, MongoDB, Google Cloud Spanner ... e um bom exemplo de dimensionamento vertical é o MySQL - Amazon RDS (A versão em nuvem do MySQL). Ele fornece uma maneira fácil de escalar verticalmente, mudando de máquinas pequenas para máquinas maiores. Este processo frequentemente envolve tempo de paragem.
Grades de Dados In-Memory como GigaSpaces XAP, Coherence etc... são frequentemente otimizadas tanto para escalas horizontais como verticais simplesmente porque elas'não estão vinculadas ao disco. Dimensionamento horizontal através de particionamento e dimensionamento vertical através de suporte multi-core.
Você pode ler mais sobre este assunto em meus posts anteriores: Scale-out vs Scale-up e The Common Principles Behind the NOSQL Alternatives
Há uma arquitetura adicional que foi't mencionada - serviços de banco de dados baseados em SQL que permitem escalonamento horizontal sem a complexidade de fragmentação manual. Estes serviços fazem o sharding em segundo plano, então eles permitem que você execute uma base de dados SQL tradicional e escalar como você faria com motores NoSQL como MongoDB ou CouchDB. Dois serviços com os quais estou familiarizado são EnterpriseDB para PostgreSQL e Xeround para MySQL. Eu vi um post por Xeround que explica por que escalar em bancos de dados SQL é difícil e como eles fazem isso de forma diferente - trate isso com um grão de sal como se fosse um post de fornecedor. Veja também Wikipedia's Cloud Database entry há uma boa explicação de SQL vs. NoSQL e serviço vs. self-hosted, uma lista de vendedores e opções de escalonamento para cada combinação ;)
Sim, escalar horizontalmente significa adicionar mais máquinas, mas também implica que as máquinas são iguais no cluster. O MySQL pode escalar horizontalmente em termos de leitura de dados, através do uso de réplicas, mas uma vez que atinge a capacidade do mem/disco do servidor, você tem que começar a dividir os dados entre os servidores. Isto torna-se cada vez mais complexo. Muitas vezes manter os dados consistentes através das réplicas é um problema, uma vez que as taxas de replicação são frequentemente demasiado lentas para acompanhar as taxas de mudança de dados.
Couchbase é também uma fantástica base de dados NoSQL Horizontal Scaling, utilizada em muitas aplicações e jogos comerciais de alta disponibilidade e indiscutivelmente a mais alta performance da categoria. Ele divide os dados automaticamente em cluster, adicionar nós é simples, e você pode usar hardware de commodity, instâncias vm mais baratas (usando Large em vez de High Mem, máquinas High Disk em AWS, por exemplo). Ele é construído a partir do Membase (Memcached), mas adiciona persistência. Além disso, no caso do Couchbase, cada nó pode ler e escrever, e são iguais no cluster, com apenas replicação failover (não replicação completa do conjunto de dados em todos os servidores como no mySQL).
Em termos de desempenho, você pode ver um excelente benchmark da Cisco: http://blog.couchbase.com/understanding-performance-benchmark-published-cisco-and-solarflare-using-couchbase-server
Aqui está um ótimo post no blog sobre Arquitetura Couchbase: http://horicky.blogspot.com/2012/07/couchbase-architecture.html

