Atunci când este practic să se utilizeze Depth-First Search (DFS) vs Breadth-First Search (BFS)?
Am înțeles diferențele dintre DFS și BFS, dar am'm a interesat să știu când l's mai practic de a utiliza una peste alta?
Ar putea cineva să dea exemple de cum DFS ar trump BFS și vice-versa?
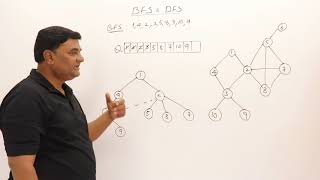










Că foarte mult depinde de structura de arbore de căutare și numărul și locația de soluții (aka căutat-pentru articole).
-
Dacă știți o soluție nu este departe de rădăcină de copac, un lățimea prima căutare (BFS) ar putea fi mai bine.
-
Dacă pomul este foarte profundă și soluții sunt rare, adâncimea prima căutare (DFS) s-ar putea lua un timp extrem de lung, dar BFS ar putea fi mai rapid.
-
Dacă pomul este foarte larg, un BFS-ar putea nevoie de prea multă memorie, astfel încât acesta ar putea fi complet imposibil.
-
Dacă soluțiile sunt frecvente, dar situat adânc în copac, BFS ar putea fi practic.
-
Dacă arbore de căutare este foarte adânc, veți avea nevoie pentru a restrânge căutarea adâncime de adâncime în primul rând de căutare (DFS), oricum (de exemplu cu iterative deepening).
Dar acestea sunt doar reguli de degetul mare; te'll, probabil, nevoia de a experimenta.
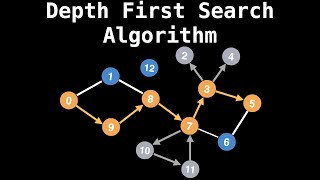
Depth-first Search
Adancime căutări sunt adesea folosite în simulări de jocuri (și de jocuri cum ar fi situațiile în lumea reală). Într-un tipic joc, puteți alege una din mai multe acțiuni posibile. Fiecare alegere duce la alte opțiuni, fiecare dintre care duce la alte alegeri, și așa mai departe într-o continuă expansiune copac în formă de grafic de posibilități.

De exemplu, în jocuri, cum ar fi Șah, joc tic-tac-toe, atunci când se decide ce să facă, vă puteți imagina mental o mișcare, apoi adversarului răspunsuri posibile, atunci răspunsurile dumneavoastră, și așa mai departe. Puteți decide ce să facă de a vedea care muta duce la cel mai bun rezultat.
Doar unele căi într-un copac joc duce la victorie. Unele conduce la un câștig de adversarul tău, atunci când vei ajunge la un astfel de final, trebuie să back-up, sau backtrack, la un precedent nod și să încerce o altă cale. În acest fel veți explora copac până când veți găsi un traseu cu o concluzie de succes. Apoi face primul pas pe această cale.
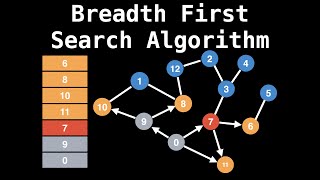
Lățimea în primul rând de căutare
Lățimea-în primul rând de căutare are o proprietate interesantă: Se constată mai întâi de toate nodurile care sunt una marginea departe de punctul de plecare, apoi toate nodurile care sunt două margini departe, și așa mai departe. Acest lucru este util dacă sunteți încercarea de a găsi calea cea mai scurtă pornind de la vertex la un anumit nod. Începe un BFS, și atunci când veți găsi noduri specificat, știi calea pe care ai urmărit până acum este cel mai scurt drum de la nodul. Dacă ar exista o mai scurtă cale, BFS-ar fi găsit-o deja.
Lățimea în primul rând de căutare poate fi utilizată pentru a găsi vecin nodurilor în rețele peer to peer ca BitTorrent, sisteme GPS pentru a găsi locații din apropiere, site-uri de socializare pentru a găsi oameni la distanță specificată și lucruri de genul asta.
Frumos Explicație din http://www.programmerinterview.com/index.php/data-structures/dfs-vs-bfs/
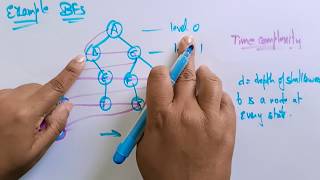
Un exemplu de BFS
Aici este un exemplu de ceea ce un BFS ar arata ca. Acest lucru este ceva de genul Nivel Pentru Arborele de Traversare în cazul în care vom folosi COADA cu abordare ITERATIVĂ (cea mai mare parte RECURSIVITATE va termina cu DFS). Numerele reprezintă ordinea în care nodurile sunt accesate într-un BFS:

Într-o adâncime de căutare în primul rând, începe de la rădăcină, și urmați una din ramurile de copac, pe cât posibil, până când nodul căutat este găsit sau te-a lovit un nod frunză ( nod cu copii). Dacă te-a lovit un nod frunză, apoi continua căutare la cel mai apropiat strămoș cu neexplorat copii.
Un exemplu de DFS
Aici este un exemplu de ceea ce un DFS ar arata ca. Cred post pentru traversare în arbore binar va începe activitatea de la nivelul Frunzelor în primul rând. Numerele reprezintă ordinea în care nodurile sunt accesate într-un DFS:

Diferențele între DFS și BFS
Compararea BFS și DFS, marele avantaj al DFS este că are mult mai mic cerințele de memorie decât BFS, pentru că nu este necesar pentru a stoca toate de copil indicii la fiecare nivel. În funcție de datele și ceea ce cautati, fie DFS sau BFS ar putea fi avantajoasă.
De exemplu, având un copac de familie dacă au fost în căutarea pentru cineva de pe copac, care este încă în viață, atunci ar fi sigur să se presupună că persoana ar fi pe partea de jos din copac. Acest lucru înseamnă că un BFS-ar lua un timp foarte lung pentru a ajunge la ultimul nivel. Un DFS, cu toate acestea, s-ar găsi scopul mai repede. Dar, dacă au fost în căutarea pentru un membru al familiei care a murit cu mult timp în urmă, atunci acea persoană ar fi mai aproape de partea de sus a copac. Apoi, un BFS ar fi, de obicei, mai repede decât un DFS. Astfel, avantajele de ori varia în funcție de datele și ceea ce căutați pentru.
Un exemplu este Facebook; Sugestie pe Prietenii prietenilor. Avem nevoie imediat de prieteni pentru sugestie unde putem folosi BFS. Poate fi găsi calea cea mai scurtă sau detectarea ciclu (folosind recursivitate) putem folosi DFS.
Lățimea în Primul rând de Căutare este, în general, cea mai bună abordare atunci când adâncimea de copac poate varia, și ai nevoie doar pentru a căuta o parte din copac pentru o soluție. De exemplu, găsirea cel mai scurt drum de la o valoare de pornire la o valoare finală este un loc bun pentru a utiliza BFS.
Adâncime de Căutare în Primul rând este frecvent utilizat atunci când aveți nevoie pentru a căuta întregul copac. L's ușor să pună în aplicare (folosind recursivitate) decât BFS, și necesită mai puțin de stat: în Timp ce BFS necesită magazin întreaga 'frontier', DFS necesită doar să stocați lista de părinte nodurile elementului curent.
DFS este mai mult spațiu-eficient decât BFS, dar poate merge la inutile adâncimi.
Numele lor sunt revelatoare: dacă nu's un mare amploare (de exemplu, mare factor de ramificare), dar foarte limitat de adâncime (de exemplu, număr limitat de "se mișcă"), apoi DFS poate fi mai preferrable să BFS.
Pe IDDFS
Trebuie menționat că nu's-o mai puțin cunoscută variantă care combină spațiul eficiența de DFS, dar (cummulatively) nivelul-pentru vizite de BFS, este iterative deepening depth-first search. Acest algoritm revizitează unele noduri, dar contribuie doar un factor constant de asimptotice diferență.
Când vă apropiați de această întrebare ca un programator, un factor iese: daca're folosind recursivitate, atunci depth-first search este simplu să pună în aplicare, pentru că tu nu't nevoie pentru a menține o suplimentare de structură de date care conține nodurile încă de a explora.
Aici's depth-first search pentru un non-graf orientat daca're stocarea "vizitat deja" informațiile din noduri:
def dfs(origin): # DFS from origin:
origin.visited = True # Mark the origin as visited
for neighbor in origin.neighbors: # Loop over the neighbors
if not neighbor.visited: dfs(next) # Visit each neighbor if not already visitedDacă stocarea "vizitat deja" informații într-o altă structură de date:
def dfs(node, visited): # DFS from origin, with already-visited set:
visited.add(node) # Mark the origin as visited
for neighbor in node.neighbors: # Loop over the neighbors
if not neighbor in visited: # If the neighbor hasn't been visited yet,
dfs(node, visited) # then visit the neighbor
dfs(origin, set())Contrast cu lățimea în primul rând de căutare în cazul în care aveți nevoie pentru a menține o separa structura de date pentru lista de noduri încă să viziteze, indiferent de ce.
Un avantaj important al BFS ar fi că acesta poate fi folosit pentru a găsi cea mai scurtă cale între oricare două noduri într-un neponderate grafic. Întrucât, nu putem folosi DFS pentru aceleași.
Pentru BFS, putem considera Facebook exemplu. Vom primi sugestii pentru a adăuga prieteni de pe FB de profil din alte altor prieteni de profil. Să presupunem că Un->B, în timp ce B->E și B->F, deci O va primi sugestie pentru E Și F. Acestea trebuie să fie folosind BFS pentru a citi până la al doilea nivel. DFS este mai mult bazat pe scenarii în cazul în care vrem să prognoză ceva bazat pe date de la sursă la destinație. După cum sa menționat deja despre șah sau sudoku. O dată am ceva diferit aici este, cred DFS ar trebui să fie utilizate pentru calea cea mai scurtă pentru că DFS va acoperi întreaga cale în primul rând, atunci putem decide cel mai bun. Dar ca BFS va folosi lacom's abordare ar putea fi aceasta pare a fi calea cea mai scurtă, dar rezultatul final poate diferi. Lasă-mă să știu dacă am înțeles greșit.
Unii algoritmi depinde de anumite proprietăți de DFS (sau BFS) la locul de muncă. De exemplu Hopcroft și Tarjan algoritm pentru găsirea 2-componente conectate profită de faptul că fiecare nod vizitat deja întâmpinate de DFS este pe calea de la rădăcină la prezent explorat nod.
Următorul text este un răspuns cuprinzător la ceea ce se cere.
În termeni simpli:
Lățimea Prima Căutare (BFS) algoritm, de la numele său "Lățimea", descoperă toți vecinii unui nod prin margini de nodul apoi se descoperă nevizitate vecinii de cele menționate anterior vecinii lor prin margini și așa mai departe, până când toate nodurile accesibile din original sursa sunt vizitate (putem continua și să ia o altă original sursa dacă au mai rămas nevizitate noduri și așa mai departe). Ca's de ce poate fi folosit pentru a găsi calea cea mai scurtă (dacă există) de la un nod (original sursă) la un alt nod dacă ponderile de marginile sunt uniforme.
Adâncimea Prima Căutare (DFS) algoritm, de la numele său "Adâncime", descoperă nevizitate vecini de pe cel mai recent descoperit nodul x prin margini. Dacă nu există nici un vecin nevizitat de la nodul x, algoritmul se abate pentru a descoperi nevizitate vecinii nodului (prin margini) din care nodul x a fost descoperit, și așa mai departe, până când toate nodurile accesibile din original sursa sunt vizitate (putem continua și să ia o altă original sursa dacă au mai rămas nevizitate noduri și așa mai departe).
Ambele BFS și DFS poate fi incompletă. De exemplu, dacă un factor de ramificare al unui nod este infinit, sau foarte mare de resurse (memorie) pentru a sprijini (de exemplu, atunci când stocarea nodurile să fie descoperit următorul), apoi BFS nu este completă chiar dacă căutat cheia poate fi la o distanță de câteva margini de original sursa. Acest infinit factor de ramificare, deoarece poate fi infinit de alegeri (vecine noduri) dintr-un nod dat pentru a descoperi. Dacă adâncimea este infinit, sau foarte mare de resurse (memorie) pentru a sprijini (de exemplu, atunci când stocarea nodurile să fie descoperit următorul), apoi DFS nu este completă chiar dacă căutat cheia poate fi cel de-al treilea vecin de original sursa. Această adâncime infinită poate fi din cauza o situație în care nu există, pentru fiecare nod, algoritmul descoperă, cel puțin o nouă alegere (vecine nod), care este nevizitate înainte.
Prin urmare, putem concluziona atunci când pentru a utiliza BFS și DFS. Să presupunem că avem de-a face cu un ușor de gestionat limitat factor de ramificare și de gestionat limitată în adâncime. Dacă căutat nod este superficială și anume accesibil după unele margini de original sursa, atunci este mai bine să utilizați BFS. Pe de altă parte, dacă căutat nod este adânc adică poate ajunge după o mulțime de muchii din original sursa, atunci este mai bine să utilizați DFS.
De exemplu, într-o rețea socială, dacă vrem să caute oameni care au interese similare de o anumită persoană, putem aplica BFS de această persoană ca un original sursa, pentru că cea mai mare parte, aceste persoane vor fi directă prieteni sau prietenii prietenilor adică una sau două margini de departe. Pe de altă parte, dacă vrem să caute oameni care au interese complet diferite de o anumită persoană, putem aplica DFS din această persoană ca un original sursa, pentru că cea mai mare parte aceste persoane vor fi foarte departe de el și anume prieten de prieten de prieten.... adică prea multe marginile departe.
Aplicații ale BFS și DFS poate varia, de asemenea, din cauza mecanismului de căutare în fiecare. De exemplu, putem folosi fie BFS (presupunând factor de ramificare este ușor de gestionat) sau DFS (presupunând că adâncimea este ușor de gestionat), atunci când vrem doar pentru a verifica accesibilitatea la un nod la altul neavând informații în cazul în care nodul poate fi. De asemenea, ambele dintre ele pot rezolva aceleași sarcini ca și sortare topologică a unui graf (dacă are). BFS poate fi folosit pentru a găsi calea cea mai scurtă, cu unitate de greutate muchii de la un nod (original sursa) la altul. Întrucât, DFS poate fi folosit pentru a epuiza toate alegerile, din cauza naturii sale de a merge în profunzime, ca și cum ai descoperi cel mai lung drum între două noduri într-un graf aciclic. De asemenea, DFS, poate fi folosit pentru ciclul de detectare într-un grafic.
În cele din urmă, dacă avem profunzime infinit și infinit factor de ramificare, putem folosi Iterative Deepening Search (IDS).
În funcție de proprietățile și BFS DFS. De exemplu,atunci când vrem să găsim calea cea mai scurtă. de obicei, vom folosi bfs,se poate garanta 'mai scurt'. dar dfs numai pot garanta că vom putea ajunge la acest punct se poate realiza acel moment ,nu poate garanta 'mai scurt'.
Cred că depinde de ce probleme se confruntă.
- drumul cel mai scurt pe grafic simplu -> bfs
- toate rezultatele posibile -> dfs
- căutare pe grafic(trata copac, martix ca un grafic prea) -> dfs ....
Pentru că Adancime Căutări folosi o stiva ca nodurile sunt prelucrate, backtracking este prevăzut cu DFS. Pentru că Lățimea în Primul rând Căutări folosi o coadă, nu o stivă, pentru a ține evidența a ceea ce nodurile sunt prelucrate, backtracking nu este prevăzută cu BFS.
Depinde de situația în care este utilizată. Ori de câte ori avem o problemă de traversare un grafic, o facem pentru un scop. Atunci când există o problemă de a găsi calea cea mai scurtă într-un neponderate grafic, sau de a găsi, dacă un graf este bipartit, putem folosi BFS. Pentru probleme de ciclu de detectare sau de orice logică necesită backtracking, putem folosi DFS.
Acesta este un exemplu bun pentru a demonstra că BFS este mai bună decât DFS în anumite cazuri. https://leetcode.com/problems/01-matrix/
Atunci când este corect implementat, ambele soluții ar trebui să viziteze celulele care au distanță mai departe decât celula curentă +1. Dar DFS este ineficient și vizitat în mod repetat aceeași celulă rezultă O(n*n) complexitate.
De exemplu,
1,1,1,1,1,1,1,1,
1,1,1,1,1,1,1,1,
1,1,1,1,1,1,1,1,
0,0,0,0,0,0,0,0,