Ce Grupate și Non-clustered index înseamnă de fapt?
Am o expunere limitată la DB si am folosit doar DB ca un programator cerere. Vreau să știu despre Cluster " și " Non grupate indici`. Am cautat pe google si ce am gasit a fost :
Un cluster de index este un tip special de index care reordona mod înregistrările din tabel sunt fizic stocate. Prin urmare, tabelul poate avea doar un cluster de index. Nodurile frunză de un cluster de index conține date pagini. Un index de grup este o tip special de index, în care ordinea logică a indicelui nu a se potrivi fizic stocate pentru a rândurile de pe disc. Nodul frunză de index de grup nu constă în pagini de date. În schimb, frunze nodurile conțin indicele de rânduri.
Ce am găsit în ASA a fost https://stackoverflow.com/questions/91688/what-are-the-differencespros-cons-between-clustered-and-non-clustered-indexes.
Poate cineva explica acest lucru în limba engleză?
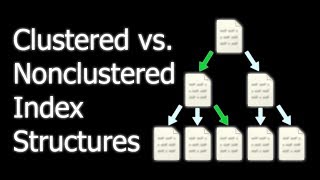








Cu un index grupat rânduri sunt stocate fizic pe disc în aceeași ordine index. Prin urmare, nu poate fi doar un singur cluster de index.
Cu un non-clustered index există o a doua listă care are indicii fizice rânduri. Puteți avea mai multe non grupate indici, deși fiecare nou indice va crește timpul necesar pentru a scrie noi recorduri.
În general, este mai rapid pentru a citi de la un cluster de index, dacă doriți pentru a obține înapoi toate coloanele. Nu trebuie să meargă mai întâi la index și apoi la masă.
Scris la o masă cu un cluster de index poate fi mai lent, dacă există o nevoie pentru a rearanja datele.
Un index grupat, înseamnă că spui baza de date pentru a stoca valori apropiate de fapt aproape una de alta pe disc. Acest lucru are avantajul de scanare rapidă / regăsire a înregistrărilor care se încadrează într-un interval de cluster valorile indicelui.
De exemplu, aveți două tabele, pentru Clienți și Pentru:
Customer
----------
ID
Name
Address
Order
----------
ID
CustomerID
PriceDacă doriți pentru a prelua rapid toate comenzile de un anumit client, ați putea dori pentru a crea un index grupat pe "CustomerID" coloana de Ordinul masă. Acest mod de înregistrări cu același CustomerID vor fi stocate fizic aproape unul de altul pe disc (cluster) care accelerează recuperarea lor.
P. S. indicele pe CustomerID va fi, evident, nu unic, astfel încât aveți nevoie pentru a adăuga un al doilea câmp pentru a "uniquify" indicele sau lasa date ocupa de asta pentru tine, dar care'e o altă poveste.
Cu privire la mai multe indexuri. Puteți avea doar un singur cluster de index pe masă, deoarece aceasta definește modul în care datele sunt fizic aranjate. Daca vrei o analogie, imaginați-vă o cameră mare, cu multe mese în ea. Puteți fie pus aceste tabele pentru a forma mai multe rânduri sau trage-le pe toate împreună pentru a forma o mare masă de conferințe, dar nu amândouă în același timp. Un tabel poate avea și alte indicii, ele vor apoi punctul de la intrări în index grupat, care la rândul său va spune în cele din urmă în cazul în care pentru a găsi datele reale.
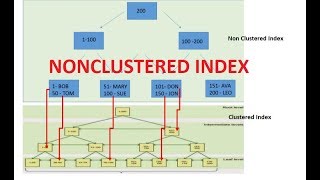
În SQL Server rând orientat de stocare ambele grupate și indici de grup sunt organizate ca B copaci. ![introduceți descrierea imaginii aici][1] ([Sursă Imagine][2]) Diferența esențială între grupate indici și non grupate indici este că frunza nivel de cluster de index este masa. Acest lucru are două implicații.
- Rândurile pe cluster de index frunze de pagini conține întotdeauna ceva pentru fiecare a (non rare) coloanele din tabel (fie valoarea, sau un pointer cu valoarea reală).
- Cluster de index este copia primară a unui tabel. Non grupate indici se poate face, de asemenea, punctul 1, cu ajutorul "INCLUD" clauze (Din SQL Server 2005) să includă în mod explicit toate non-cheie coloane, dar acestea sunt secundare reprezentări și există întotdeauna o altă copie a datelor în jurul valorii de (tabelul în sine).
CREATE TABLE T
(
A INT,
B INT,
C INT,
D INT
)
CREATE UNIQUE CLUSTERED INDEX ci ON T(A,B)
CREATE UNIQUE NONCLUSTERED INDEX nci ON T(A,B) INCLUDE (C,D)Cei doi indici de mai sus vor fi aproape identice. Cu nivelul superior indicelui de pagini care conțin valorile pentru cheie coloane A, B și frunza nivel pagini conțin `a,B,C,D
Nu poate fi decât un index grupat pe masă, pentru că rândurile de date ele pot fi sortate în doar o singură comandă. Citatul de mai sus din SQL Server books online provoacă multă confuzie În opinia mea, ar fi mult mai bine formulat ca. Nu poate fi decât un index grupat pe masă, pentru că la nivelul frunzelor rânduri de cluster de index sunt tabelul de rânduri. Cărțile citat on-line nu este incorect, dar ar trebui să fie clar că "sortare" de ambele non grupate și grupate indici este logic, nu fizică. Daca ai citit paginile la nivelul frunzelor, urmând legate listă și a citit rânduri pe pagină în slot matrice pentru atunci veți citi indexul rânduri în ordine sortată dar din punct de vedere fizic pagini nu pot fi sortate. De obicei a avut loc convingerea că, cu un index grupat rândurile sunt întotdeauna stocate fizic pe disc în aceeași ordine ca și index cheie * este falsă. Acest lucru ar fi absurd ca în aplicare. De exemplu, dacă un rând este introdus în mijlocul unei 4GB tabel SQL Server nu nu** trebuie să copiați 2GB de date în fișier pentru a face loc pentru nou introduse consecutiv . În loc de o fracțiune de pagină apare. Fiecare pagină, la nivelul frunzelor de ambele grupate și non grupate indici are adresa (
File:Pagina) a următoare și pagina anterioară, în logică cheie ordine. Aceste pagini nu trebuie să fie adiacente sau din cheia de comanda. de exemplu, pe pagina de legat în lanț ar putea fi1:2000 <-> 1:157 <-> 1:7053Atunci când o pagină split, se întâmplă o nouă pagină este alocat de la oriunde în filegroup (fie de un amestec de măsură, pentru mese mici, sau un non gol uniformă măsura în care aparțin acelui obiect sau un nou alocat uniformă măsură). Acest lucru ar putea să nu fie în același fișier dacă fișierul grup conține mai mult de unul. Gradul în care ordinea logică și contiguitate diferă de la idealizată fizice versiune este gradul de logică fragmentare. Într-un nou create baze de date cu un singur fișier am fugit următoarele.
CREATE TABLE T
(
X TINYINT NOT NULL,
Y CHAR(3000) NULL
);
CREATE CLUSTERED INDEX ix
ON T(X);
GO
--Insert 100 rows with values 1 - 100 in random order
DECLARE @C1 AS CURSOR,
@X AS INT
SET @C1 = CURSOR FAST_FORWARD
FOR SELECT number
FROM master..spt_values
WHERE type = 'P'
AND number BETWEEN 1 AND 100
ORDER BY CRYPT_GEN_RANDOM(4)
OPEN @C1;
FETCH NEXT FROM @C1 INTO @X;
WHILE @@FETCH_STATUS = 0
BEGIN
INSERT INTO T (X)
VALUES (@X);
FETCH NEXT FROM @C1 INTO @X;
ENDApoi verificat aspect de pagină cu
SELECT page_id,
X,
geometry::Point(page_id, X, 0).STBuffer(1)
FROM T
CROSS APPLY sys.fn_PhysLocCracker( %% physloc %% )
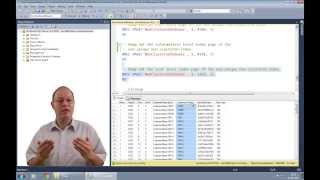
ORDER BY page_idRezultatele au fost peste tot. Primul rând, în cheia de comandă (cu valoarea 1 - a evidențiat cu săgeata de mai jos) a fost aproape pe ultima pagină fizic. ![introduceți descrierea imaginii aici][4] Fragmentarea poate fi redus sau eliminat prin reconstruirea sau reorganizarea unui indice pentru a crește corelație între ordinea logică și fizică ordine. După rularea
ALTER INDEX ix ON T REBUILD;Am si eu urmatoarea ![introduceți descrierea imaginii aici][5] Dacă tabelul are nici un cluster de index este numit un heap. Non grupate indici poate fi construit fie pe un heap sau un cluster de index. Ele conțin întotdeauna un rând de localizare înapoi la masa de bază. În cazul unui heap aceasta este o fizică rând de identificare (rid) și este format din trei componente (Fișier:Pagina:Slot). În cazul unui Cluster de index rândul locator este logic (the cluster de index cheie). Pentru acest din urmă caz dacă non index grupat deja include în mod natural CI coloană cheie(s), fie ca NCI cheie coloane sau "INCLUD" -d coloane atunci nimic nu este adăugat. În caz contrar lipsă CI coloană cheie(s) în tăcere se adaugă la NCI. SQL Server asigură întotdeauna că cheia coloane sunt unice pentru ambele tipuri de index. Mecanismul în care acest lucru este impus de indici care nu sunt declarate ca unic diferă între cele două tipuri de index cu toate acestea. Grupate indici obține un uniquifier adăugată pentru toate rândurile cu valori cheie duplicat existent rând. Acesta este doar un ascendent număr întreg. Pentru non grupate indici care nu sunt declarate ca unic SQL Server în tăcere adaugă pe rând de localizare în non-clustered index cheie. Acest lucru este valabil pentru toate rândurile, nu doar cei care sunt de fapt duplicate. Grupată vs non grupate nomenclatura este, de asemenea, folosit pentru coloana magazin de indici. Lucrarea [Accesorii pentru SQL Server Coloana Magazine][6] ale americii
Deși coloana stoca date nu este cu adevărat "cluster" pe orice tastă, am a decis să-și păstreze tradiționale SQL Server convenția de trimitere pentru indicele principal ca un cluster de index.
Îmi dau seama că este o întrebare foarte veche, dar m-am gandit sa va ofer o analogie pentru a ajuta la ilustrarea bine răspunsurile de mai sus.
CLUSTER DE INDEX
Dacă intri într-o bibliotecă publică, veți găsi că cărțile sunt aranjate într-o anumită ordine (cel mai probabil Sistemul Zecimal Dewey, sau DDS). Aceasta corespunde "index grupat" din cărți. Dacă DDS# pentru cartea pe care vreau s 005.7565 F736s, vei începe prin localizarea rând de rafturi, care este etichetat001-099sau ceva de genul asta. (Acest endcap semn la sfârșitul stiva corespunde unei "nod intermediar" în index.) În cele din urmă vă va detalia specifice raft etichetate005.7450 - 005.7600`, atunci ar scanare până când a găsit o carte cu cele specificate DDS#, și în acel moment ați găsit cartea ta.
NON-CLUSTERED INDEX
Dar dacă tu nu ai n't intră în bibliotecă cu DDS# de cartea ta memorat, atunci ai nevoie de un al doilea index pentru a vă ajuta. În vremurile de demult le-ar găsi în fața bibliotecii un minunat biroul de sertare cunoscut ca "Catalog de Carte". În ea au fost mii de 3x5 carduri, unul pentru fiecare carte, sortate în ordine alfabetică (după titlu, probabil). Aceasta corespunde "non-clustered index". Aceste cataloage au fost organizate într-o structură ierarhică, astfel încât fiecare sertar va fi etichetat cu gama de carduri conținea (Ka - Ba, de exemplu; de exemplu, "nod intermediar"). Încă o dată, s-ar putea face până ai găsit cartea ta, dar, în acest caz, odată ce ați găsit-o (am.e, "nod frunză"), nu't avea cartea în sine, ci doar un card cu o index numărul (DDS#) cu care ai putea găsi cartea în cluster de index.
Desigur, nimic nu s-ar opri bibliotecar la xerox toate cărțile și de sortare-le într-o ordine diferită de la un card separat în catalog. (De obicei, au fost cel puțin două astfel de cataloage: unul clasificate în funcție de nume autor, și unul de titlu.) În principiu, ai putea avea cât mai multe dintre aceste "non-cluster" indicii, după cum doriți.
Găsiți mai jos câteva caracteristici ale grupate și non-cluster indici:
Grupate Indici
- Grupate indici sunt indici care identifica în mod unic rânduri într-un tabel SQL.
- Fiecare tabel poate avea exact un cluster de index.
- Puteți crea un index grupat, care acoperă mai mult de o coloană. De exemplu: create Index index_name(col1, col2, col.....)`.
- În mod implicit, o coloană cu o cheie primară are deja un cluster de index.
Non-cluster Indici
- Non-cluster indexurile sunt ca simple indicii. Ele sunt folosite doar pentru recuperarea rapidă a datelor. Nu sunt sigur de a avea date unice.
Un foarte simplu, non-tehnic regula de degetul mare ar fi că grupate indici sunt de obicei folosite pentru cheie primară (sau, cel puțin, un unic coloană) și că non-cluster sunt folosite pentru alte situații (poate o cheie externă). Într-adevăr, SQL Server va implicit a crea un index grupat pe cheie primară coloana(e). Cum te-au învățat, grupată indicele se referă la modul în care datele sunt fizic sortate pe disc, ceea ce înseamnă că's un bun toate-a rundă de alegere pentru cele mai multe situații.
Cluster De Index
Un cluster de index a determina ordinea fizică a DATELOR într-un tabel.Pentru acest motiv un tabel au doar 1 cluster de index.
"dicționar" Nu este nevoie de orice alt Index, deja Index în funcție de cuvinte
Index De Grup
Un non-clustered index este analog cu un index într-o Carte.Datele sunt stocați într-un singur loc. la indicele este magazin într-un alt loc și index au pointer la locația de stocare a datelor.Pentru acest motiv, o masă au mai mult de 1 index de Grup.
- "Chimie carte" la mirat există un index separat la punct Capitolul locație și La "END" nu este un alt Indice arătând CUVINTE comune locație
Cluster De Index
Grupate indici fel și stoca datele rândurile din tabel sau vizualizare bazat pe valori cheie. Acestea sunt coloanele incluse în indicele definiție. Nu poate fi doar un index grupat pe masă, pentru că rândurile de date pot fi sortate în doar o singură comandă.
Singurul moment de rânduri de date într-un tabel sunt stocate în ordine sortată este atunci când tabelul conține un index grupat. Atunci când un tabel are un index grupat, masa este numit un cluster de masă. Dacă un tabel are nici un index grupat, sa rândurile de date sunt stocate într-un neordonate structură numită heap.
De grup
Grup indici au o structură separată de rânduri de date. Un index de grup conține index de grup valori-cheie și fiecare valoare de cheie de intrare are un pointer la șirul de date care conține valoarea cheii. Indicatorul de la un indice de rând într-un index de grup la un rând de date este numit un rând de localizare. Structura rând de localizare depinde de pagini de date sunt stocate într-un heap sau un cluster de masă. Pentru un heap, un rând de localizare este un pointer la rând. Pentru un cluster de masă, rândul locator este grupată index cheie.
Puteți adăuga nonkey coloane la nivelul frunzelor de index de grup pentru by-pass existente index cheie limite, și să execute pe deplin acoperite, indexate, interogări. Pentru mai multe informații, consultați Crearea Indici cu Coloane Incluse. Pentru detalii despre index cheie limitele vedea Capacitate Maximă Specificațiile pentru SQL Server.
Lasă-mă să ofer o definiție scrisă pe "clustering index", care este luat de la 15.6.1 de Sisteme de baze de Date: Cartea Completă:
de asemenea, Putem vorbi de clustering indici, care sunt indicii privind un atribut sau atribute, astfel încât toate tupluri cu o valoare fixă pentru tasta de căutare a acestui indice apar la aproximativ după câteva blocuri ca le pot deține.
Pentru a înțelege definiția, să's ia o privire la Exemplul 15.10 oferite de manual:
O raport
R(a,b)care este sortata pe atributul " a " și stocate în scopul, ambalate în blocuri, este cu siguranță clusterd. Un index pe " a " este un clustering index, deoarece pentru un anumita-valoarea a1, toate tuplurile cu că valoarea " o " sunt consecutive. Astfel, ele apar ambalate în blocuri, execept, eventual, pentru prima și ultima blocuri care conțina-valoarea a1, după cum a sugerat în Fig.15.14. Cu toate acestea, un index pe b puțin probabil să fie de clustering, deoarece tupluri cu un fix " b " -valoarea va fi răspândit peste tot în fișier dacă valorile " a " și " b " sunt foarte strâns corelate.

Rețineți că definiția nu se aplica blocuri de date trebuie să fie contigue de pe disc; se spune doar tupluri cu cheie de căutare sunt ambalate în cât mai puține blocuri de date posibil.
Un concept legat e cluster relația. O relație este "cluster" dacă tupluri sunt ambalate în aproximativ blocuri cât mai puține posibil dețin acele tupluri. Cu alte cuvinte, dintr-un disc bloca perspectiva, în cazul în care conține tupluri din diferite relații, atunci aceste relații nu pot fi grupate (de exemplu, există o mult mai dotat mod de a stoca astfel de relație de pompare tuplurile din relatia asta de la alte blocuri disc cu tupluri care nu't aparțin relației în actualul disc bloc). În mod clar, `R(a,b) în exemplul de mai sus este pus în cluster.
Pentru a conecta două concepte împreună, un cluster legătură poate avea un clustering index și nonclustering index. Cu toate acestea, pentru non-cluster raport, clustering index nu este posibilă decât dacă indicele este construit pe partea de sus de cheia primară a relației.
"Grup" ca un cuvânt este raspandit peste toate abstractizare niveluri de stocare de date secundare (trei niveluri de abstractizare: tupluri, blocuri, fișier). Un concept numit "[cluster file][3]", care descrie dacă un fișier (o abstractizare a unui grup de blocuri (unul sau mai multe blocuri disc)) conține tupluri dintr-o relație sau diferite relații. Nu't se referă la gruparea index concept ca este la nivel de fișier.
Cu toate acestea, unele material didactic îi place să se definească clustering index bazat pe clustere de fișier definiție. Cele două tipuri de definiții sunt la fel pe cluster relație nivel, indiferent dacă ele definesc grupate relație în termeni de date de pe disc bloc sau fișier. Din link-ul de la prezentul alineat,
Un index pe atribut(e) O pe un fișier este o grupare de index atunci când: Toate tupluri cu valoare de atribut a = a sunt stocate secvențial (= consecutiv) în fișierul de date
Stocarea tupluri consecutiv este la fel cu a spune "tupluri sunt ambalate în aproximativ blocuri cât mai puține posibil dețin acele tupluri" (cu diferență minoră pe unul vorbind despre fișier, alte vorbind despre disc). L's pentru stocarea tuplu consecutiv este modul de a obține "ambalate în aproximativ blocuri cât mai puține posibil dețin acele tupluri".
[3]: http://www.mathcs.emory.edu/~cheung/Cursuri/554/Programa/2 discuri de dimensiuni fixe.html#grupate
Cluster De Index: Restricție de Cheie primară creează grupate Indice în mod automat dacă nu cluster de Index există deja pe masă. Datele reale de cluster de index pot fi stocate la nivelul frunzelor de Index.
Non-Clustered Index: Datele reale de non cluster de index nu este direct găsit la nod frunză, în schimb, trebuie să ia un pas suplimentar pentru a găsi, pentru că are doar valori de rând locatoare orientate spre date reale. Non-clustered Index poate't fi sortate ca cluster de index. Pot exista mai multe non grupate indici de pe masă, de fapt, depinde de versiunea de sql server folosim. Practic Sql server 2005 permite 249 Non Grupate Indici și pentru versiunile de mai sus ca 2008, 2016 vă permite 999 Non Grupate Indici de pe masă.