В чем разница между utf8_general_ci и utf8_unicode_ci
Есть ли различия в производительности между utf8_general_ci и utf8_unicode_ci?













Эти две коллизии предназначены для кодировки символов UTF-8. Различия заключаются в том, как сортируется и сравнивается текст.
Примечание: Вам следует использовать utf8mb4, а не utf8. Они оба относятся к кодировке UTF-8, но более старая utf8 имела специфическое для MySQL ограничение, запрещающее использование символов с номерами выше 0xFFFD..
Примечание: Новые версии MySQL имеют обновленные правила сортировки Unicode, доступные под такими именами, как utf8mb4_0900_ci для правил, основанных на Unicode 9.0 - и не имеющие эквивалентного общего варианта.
Ключевые отличия
utf8mb4_unicode_ciоснован на официальных правилах Unicode для универсальной сортировки и сравнения, которые точно сортируют в широком диапазоне языков.utf8mb4_general_ci- это упрощенный набор правил сортировки, который стремится сделать все настолько хорошо, насколько это возможно, используя при этом множество сокращений, направленных на повышение скорости. Он не следует правилам Unicode и приведет к нежелательной сортировке или сравнению в некоторых ситуациях, например, при использовании определенных языков или символов. На современных серверах этот прирост производительности будет практически незначительным. Он был разработан в те времена, когда серверы имели лишь малую часть производительности процессора современных компьютеров. Примечание: сейчас существует обновленная версияutf8mb4_unicode_ciпод названиемutf8mb4_0900_ai_ci- она основана на изменениях в Unicode версии 9.0, и также, очевидно, быстрее. В ней принята новая схема именования, где0900- это версия Unicode, аaiозначает нечувствительность к ударениям - как и в предыдущейutf8mb4_unicode_ci, ударения в буквах не считаются значимыми. Преимуществаutf8mb4_unicode_ciпередutf8mb4_general_ciutf8mb4_unicode_ci, использующий правила Unicode для сортировки и сравнения, применяет довольно сложный алгоритм для правильной сортировки в широком диапазоне языков и при использовании широкого спектра специальных символов. Эти правила должны принимать во внимание специфические языковые соглашения; не все сортируют свои символы в том, что мы называем 'алфавитным порядком'. Что касается латинских (то есть "европейских") языков, то разница между сортировкой Unicode и упрощенной сортировкойutf8mb4_general_ciв MySQL невелика, но все же есть несколько различий:- Например, сортировка Unicode сортирует "ß" как "ss", и "Œ" как "OE", как обычно хотят люди, использующие эти символы, тогда как
utf8mb4_general_ciсортирует их как отдельные символы (предположительно как "s" и "e" соответственно). - Некоторые символы Unicode определены как игнорируемые, что означает, что они не должны учитываться при сортировке, и сравнение должно перейти к следующему символу.
utf8mb4_unicode_ciобрабатывает их должным образом. В нелатинских языках, таких как азиатские языки или языки с другими алфавитами, может быть гораздо больше различий между сортировкой Unicode и упрощенной сортировкойutf8mb4_general_ci. Пригодностьutf8mb4_general_ciбудет сильно зависеть от используемого языка. Для некоторых языков она будет совершенно неадекватной. Что вы должны использовать? Почти наверняка больше нет причин использоватьutf8mb4_general_ci, поскольку мы уже оставили позади тот момент, когда скорость процессора достаточно низка, чтобы разница в производительности была существенной. Ваша база данных почти наверняка будет ограничена другими узкими местами, кроме этого. В прошлом некоторые люди рекомендовали использоватьutf8mb4_general_ciтолько в тех случаях, когда точная сортировка была достаточно важна, чтобы оправдать затраты на производительность. Сегодня эти затраты на производительность практически исчезли, и разработчики стали относиться к интернационализации более серьезно. Можно привести аргумент, что если скорость для вас важнее точности, то вы можете вообще не делать сортировку. Тривиально сделать алгоритм быстрее, если вам не нужна его точность. Так чтоutf8mb4_general_ci- это компромисс, который, вероятно, не нужен по причинам скорости и, вероятно, также не подходит по причинам точности. Еще один момент, который я хотел бы добавить: даже если вы знаете, что ваше приложение поддерживает только английский язык, ему все равно может потребоваться работать с именами людей, которые часто могут содержать символы, используемые в других языках, в которых так же важно правильно сортировать. Использование правил Unicode для всех случаев позволяет быть уверенным в том, что очень умные люди из Unicode приложили все усилия, чтобы сортировка работала правильно. Что означают эти части** Во-первых,ciпредназначен для сортировки и сравнения без учета регистра. Это означает, что она подходит для текстовых данных, где регистр не важен. Другие типы сортировки -cs(чувствительная к регистру) для текстовых данных, где регистр важен, иbin, для тех случаев, когда кодировка должна совпадать, бит в бит, что подходит для полей, которые действительно являются закодированными двоичными данными (включая, например, Base64). Сортировка с учетом регистра приводит к странным результатам, а сравнение с учетом регистра может привести к дублированию значений, отличающихся только регистром букв, поэтому колляции с учетом регистра выходят из употребления для текстовых данных - если для вас важен регистр, то, вероятно, важна и игнорируемая пунктуация и так далее, и бинарная колляция может быть более подходящей. Далее,unicodeилиgeneralотносится к конкретным правилам сортировки и сравнения - в частности, к способу нормализации или сравнения текста. Существует множество различных наборов правил для кодировки символов utf8mb4, при этомunicodeиgeneral- это два набора правил, которые пытаются хорошо работать во всех возможных языках, а не в одном конкретном. Различия между этими двумя наборами правил и являются темой данного ответа. Обратите внимание, чтоunicodeиспользует правила из Unicode 4.0. Последние версии MySQL добавляют наборы правилunicode_520, использующие правила из Unicode 5.2, и0900(опуская часть "unicode_"), использующие правила из Unicode 9.0. И, наконец,utf8mb4- это, конечно, внутренняя кодировка символов. В этом ответе я говорю только о кодировках, основанных на Unicode.
Я хотел бы знать, какова разница в производительности между использованием utf8_general_ci и utf8_unicode_ci, но я не нашел каких-либо критериев, перечисленных в интернете, поэтому я решил создать себе ориентиры.
Я создал очень простую таблицу с 500 000 строк:
CREATE TABLE test(
ID INT(11) DEFAULT NULL,
Description VARCHAR(20) DEFAULT NULL
)
ENGINE = INNODB
CHARACTER SET utf8
COLLATE utf8_general_ci;Затем я наполнил его случайными данными при выполнении этой хранимой процедуры:
CREATE PROCEDURE randomizer()
BEGIN
DECLARE i INT DEFAULT 0;
DECLARE random CHAR(20) ;
theloop: loop
SET random = CONV(FLOOR(RAND() * 99999999999999), 20, 36);
INSERT INTO test VALUES (i+1, random);
SET i=i+1;
IF i = 500000 THEN
LEAVE theloop;
END IF;
END LOOP theloop;
ENDЗатем я создал следующие хранимые процедуры для ориентира простой выберите, Выбрать с как, и сортировки (Выберите с порядок):
CREATE PROCEDURE benchmark_simple_select()
BEGIN
DECLARE i INT DEFAULT 0;
theloop: loop
SELECT *
FROM test
WHERE Description = 'test' COLLATE utf8_general_ci;
SET i = i + 1;
IF i = 30 THEN
LEAVE theloop;
END IF;
END LOOP theloop;
END;
CREATE PROCEDURE benchmark_select_like()
BEGIN
DECLARE i INT DEFAULT 0;
theloop: loop
SELECT *
FROM test
WHERE Description LIKE '%test' COLLATE utf8_general_ci;
SET i = i + 1;
IF i = 30 THEN
LEAVE theloop;
END IF;
END LOOP theloop;
END;
CREATE PROCEDURE benchmark_order_by()
BEGIN
DECLARE i INT DEFAULT 0;
theloop: loop
SELECT *
FROM test
WHERE ID > FLOOR(1 + RAND() * (400000 - 1))
ORDER BY Description COLLATE utf8_general_ci LIMIT 1000;
SET i = i + 1;
IF i = 10 THEN
LEAVE theloop;
END IF;
END LOOP theloop;
END;В хранимых процедурах выше использовать utf8_general_ci сортировки, но, конечно, во время тестов я использовал как utf8_general_ci и utf8_unicode_ci.
Я назвал каждой хранимой процедуры 5 раз для каждой сортировки (5 раз по utf8_general_ci и 5 раз по utf8_unicode_ci), а затем рассчитаны средние значения.
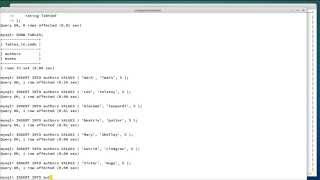
Мои результаты:
benchmark_simple_select()
- с
utf8_general_ci: 9,957 МС - с
utf8_unicode_ci: 10,271 МС
В этот тест, используя utf8_unicode_ci медленнее utf8_general_ci на 3,2%.
benchmark_select_like()
- с
utf8_general_ci: 11,441 МС - с
utf8_unicode_ci: 12,811 МС
В этот тест, используя utf8_unicode_ci медленнее utf8_general_ci на 12%.
benchmark_order_by()
- с
utf8_general_ci: 11,944 МС - с
utf8_unicode_ci: 12,887 МС
В этот тест, используя utf8_unicode_ci медленнее utf8_general_ci на 7,9%.
См. руководство mysql, раздел Наборы символов Unicode:
Для любого набора символов Unicode, операции, выполняемые с использованием _general_ci collation быстрее, чем для _unicode_ci collation. Например, сравнение для набора символов >. utf8_general_ci быстрее, но немного менее корректны, чем сравнения для колляции utf8_unicode_ci. Причина причина этого в том, что utf8_unicode_ci поддерживает такие отображения, как как расширения; то есть, когда один символ сравнивается как равный с комбинации других символов. Для например, в немецком и некоторых других языках "ß" равен "ss". utf8_unicode_ci также поддерживает. сокращения и игнорируемые символы. utf8_general_ci - это унаследованная коллизия. которая не поддерживает расширения, сокращения или игнорируемые символы. Она может делать только > сравнения один-к-одному. сравнения между символами.
Итак, подведем итог: utf_general_ci использует меньший и менее корректный (согласно стандарту) набор сравнений, чем utf_unicode_ci, который должен реализовывать весь стандарт. Набор general_ci будет быстрее, потому что требуется меньше вычислений.
В кратких словах:
Если вам нужно лучше порядок сортировки - используйте utf8_unicode_ci (это предпочтительный способ),
но если вы крайне заинтересованы в эффективности использования utf8_general_ci, но знаю, что он немного устарел.
Различия в плане производительности очень небольшой.
Некоторые детали (ЛП)
Как мы можем прочитать здесь (Питер Гулуцэном) есть разница на сортировка/сравнение польских букву "Ł" И (Л с инсультом в формате HTML Эку: Ł) (строчными буквами: "по ł" в формате HTML Эку: ł) - у нас есть следующее предположение:
utf8_polish_ci Ł greater than L and less than M
utf8_unicode_ci Ł greater than L and less than M
utf8_unicode_520_ci Ł equal to L
utf8_general_ci Ł greater than ZŁ в польском языке буква стоит после буквы Л и до М. Никому такого кодирования лучше или хуже - это зависит от ваших потребностей.
Судя по этому посту, есть значительно большие преимущества в плане производительности на MySQL 5.7 при использовании utf8mb4_general_ci вместо utf8mb4_unicode_ci: https://www.percona.com/blog/2019/02/27/charset-and-collation-settings-impact-on-mysql-performance/




