¿Por qué se permite la ejecución de código Java en comentarios con determinados caracteres Unicode?
El siguiente código produce la salida "¡Hola Mundo!" (no, en serio, pruébalo).
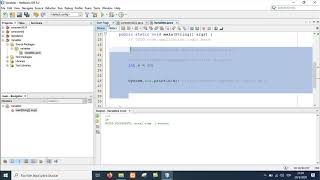
public static void main(String... args) {
// The comment below is not a typo.
// \u000d System.out.println("Hello World!");
}La razón de esto es que el compilador de Java analiza el carácter Unicode \u000d como una nueva línea y se transforma en:
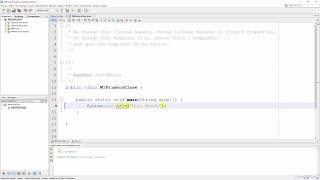
public static void main(String... args) {
// The comment below is not a typo.
//
System.out.println("Hello World!");
}Por lo tanto, el resultado es un comentario que se "ejecuta".
Dado que esto puede ser utilizado para "ocultar" código malicioso o cualquier cosa que un programador malvado pueda concebir, ¿por qué se permite en los comentarios?
¿Por qué está permitido por la especificación de Java?







La decodificación de Unicode tiene lugar antes de cualquier otra traducción léxica. El beneficio clave de esto es que hace que sea trivial ir y venir entre ASCII y cualquier otra codificación. Ni siquiera es necesario averiguar dónde empiezan y terminan los comentarios.
Como se indica en JLS Sección 3.3 esto permite que cualquier herramienta basada en ASCII pueda procesar los archivos fuente:
[...] El lenguaje de programación Java especifica una forma estándar de transformar un programa escrito en Unicode a ASCII que cambia un programa a una forma que puede ser procesada por herramientas basadas en ASCII. [...]
Esto proporciona una garantía fundamental para la independencia de la plataforma (independencia de los conjuntos de caracteres soportados) que siempre ha sido un objetivo clave para la plataforma Java.
El hecho de poder escribir cualquier carácter Unicode en cualquier lugar del archivo es una característica muy interesante, y especialmente importante en los comentarios, cuando se documenta código en lenguajes no latinos. El hecho de que pueda interferir con la semántica de maneras tan sutiles es sólo un (desafortunado) efecto secundario.
Hay muchas trampas sobre este tema y Java Puzzlers de Joshua Bloch y Neal Gafter incluye la siguiente variante:
¿Es este un programa Java legal? Si es así, ¿qué imprime?
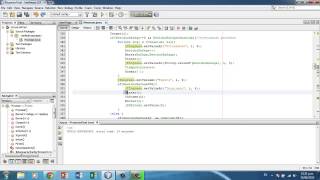
\u0070\u0075\u0062\u006c\u0069\u0063\u0020\u0020\u0020\u0020 \u0063\u006c\u0061\u0073\u0073\u0020\u0055\u0067\u006c\u0079 \u007b\u0070\u0075\u0062\u006c\u0069\u0063\u0020\u0020\u0020 \u0020\u0020\u0020\u0020\u0073\u0074\u0061\u0074\u0069\u0063 \u0076\u006f\u0069\u0064\u0020\u006d\u0061\u0069\u006e\u0028 \u0053\u0074\u0072\u0069\u006e\u0067\u005b\u005d\u0020\u0020 \u0020\u0020\u0020\u0020\u0061\u0072\u0067\u0073\u0029\u007b \u0053\u0079\u0073\u0074\u0065\u006d\u002e\u006f\u0075\u0074 \u002e\u0070\u0072\u0069\u006e\u0074\u006c\u006e\u0028\u0020 \u0022\u0048\u0065\u006c\u006c\u006f\u0020\u0077\u0022\u002b \u0022\u006f\u0072\u006c\u0064\u0022\u0029\u003b\u007d\u007d
(Este programa resulta ser un simple programa "Hola Mundo").
En la solución del rompecabezas, señalan lo siguiente:
Más seriamente, este rompecabezas sirve para reforzar las lecciones de los tres anteriores: Los escapes Unicode son esenciales cuando necesitas insertar en tu programa caracteres que no pueden ser representados de ninguna otra manera. Evítalos en todos los demás casos.
El escape \u000d termina un comentario porque los escapes \u se convierten uniformemente en los caracteres Unicode correspondientes antes de que el programa sea tokenizado. También se puede usar "u0057" en lugar de "//" para "comenzar" un comentario.
Esto es un error de su IDE, que debería resaltar la línea para dejar claro que el \u000d termina el comentario.
Esto es también un error de diseño en el lenguaje. No puede ser corregido ahora, porque eso rompería los programas que dependen de él. Los escapes \u deberían ser convertidos al correspondiente carácter Unicode por el compilador sólo en contextos en los que eso "tiene sentido" (literales de cadena e identificadores, y probablemente en ningún otro lugar) o deberían haber sido prohibidos para generar caracteres en el rango U+0000-007F, o ambos. Cualquiera de esas semánticas habría evitado que el comentario terminara con el escape \u000d, sin interferir con los casos en los que los escapes \u son útiles -nótese que eso incluye el uso de los escapes \u dentro de los comentarios como una forma de codificar los comentarios en una escritura no latina, porque el editor de texto podría tener una visión más amplia de dónde los escapes \u son significativos que el compilador. (Sin embargo, no conozco ningún editor o IDE que muestre los escapes \u como los caracteres correspondientes en cualquier contexto).
Hay un error de diseño similar en la familia C,1 donde la barra invertida-nueva línea se procesa antes de que se determinen los límites de los comentarios, así que, por ejemplo
// this is a comment \
this is still in the comment!Traigo esto a colación para ilustrar que resulta fácil cometer este error de diseño en particular, y no darse cuenta de que es un error hasta que es demasiado tarde para corregirlo, si estás acostumbrado a pensar en la tokenización y el análisis sintáctico de la forma en que los programadores de compiladores piensan en la tokenización y el análisis sintáctico. Básicamente, si usted ya ha definido su gramática formal y luego alguien viene con un caso sintáctico especial — trigrafos, backslash-newline, codificación de caracteres Unicode arbitrarios en archivos de origen limitados a ASCII, lo que sea — que necesita ser encajado, es más fácil añadir un pase de transformación antes del tokenizador que redefinir el tokenizador para prestar atención a donde tiene sentido usar ese caso especial.
1 Para los pedantes: Soy consciente de que este aspecto de C fue 100% intencionado, con el razonamiento — no me lo estoy inventando — de que te permitiría forzar mecánicamente el código con líneas arbitrariamente largas en tarjetas perforadas. Aun así, fue una decisión de diseño incorrecta.
Coincido con @zwol en que es un error de diseño; pero lo critico aún más.
El escape \u es útil en los literales de cadena y char; y ese es el único lugar en el que debería existir. Debería ser manejado de la misma manera que otros escapes como \n; y "\u000A" debería significar exactamente "\n".
No tiene ningún sentido tener "uxxxx" en los comentarios - nadie puede leerlo.
Del mismo modo, no tiene sentido usar "uxxxx" en otras partes del programa. La única excepción es probablemente en las APIs públicas que son forzadas a contener algunos caracteres no-ascii - ¿cuál es la última vez que hemos visto eso?
Los diseñadores tenían sus razones en 1995, pero 20 años después, esta parece ser una elección equivocada.
*(pregunta a los lectores - ¿por qué esta pregunta sigue recibiendo nuevos votos? ¿está esta pregunta enlazada desde algún lugar popular?)



