Kāpēc ir atļauts izpildīt Java kodu komentāros ar noteiktām Unicode rakstzīmēm?
Šāds kods rada izvades "Hello World!" (nē, tiešām, pamēģiniet to).
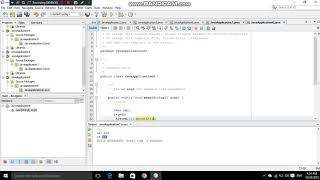
public static void main(String... args) {
// The comment below is not a typo.
// \u000d System.out.println("Hello World!");
}Iemesls tam ir tāds, ka Java kompilators analizē Unicode rakstzīmi \u000d kā jaunu rindu un pārveido to:
public static void main(String... args) {
// The comment below is not a typo.
//
System.out.println("Hello World!");
}Tā rezultātā komentārs tiek "izpildīts".
Tā kā to var izmantot, lai "paslēptu" ļaunprātīgu kodu vai jebko citu, ko spēj izdomāt ļauns programmētājs, kāpēc tas ir atļauts komentāros**?
Kāpēc tas ir atļauts Java specifikācijā?






![Character Set in Java | ASCII vs Unicode [HINDI]](https://img.youtube.com/vi/NFjYOFSVieA/mqdefault.jpg)








Unicode dekodēšana notiek pirms jebkuras citas leksiskās tulkošanas. Galvenais ieguvums ir tas, ka tas ļauj triviāli pāriet no ASCII uz jebkuru citu kodējumu. Jums pat nav jānoskaidro, kur sākas un beidzas komentāri!
Kā norādīts JLS 3.3. sadaļā, tas ļauj jebkuram uz ASCII balstītam rīkam apstrādāt avota failus:
Java programmēšanas valoda nosaka standarta veidu, kā Unicode rakstītu programmu pārveidot ASCII, kas pārveido programmu tādā formā, kuru var apstrādāt ar ASCII bāzētiem rīkiem. [...]
Tas sniedz pamatgarantijas platformas neatkarībai (neatkarība no atbalstāmajām rakstzīmju kopām), kas vienmēr ir bijis viens no galvenajiem Java platformas mērķiem.
Iespēja ierakstīt jebkuru Unicode rakstzīmi jebkurā vietā failā ir lieliska iespēja, un tā ir īpaši svarīga komentāros, dokumentējot kodu valodās, kas nav latīņu valodas. Tas, ka tā var tik smalki ietekmēt semantiku, ir tikai (neveiksmīgs) blakusefekts.
Šai tēmai ir daudz "gotchas", un Joshua Bloch un Neal Gafter Java Puzzlers ir minējuši šādu variantu:
Vai šī ir legāla Java programma? Ja jā, ko tā drukā?
\u0070\u0075\u0062\u006c\u0069\u0063\u0020\u0020\u0020\u0020 \u0063\u006c\u0061\u0073\u0073\u0020\u0055\u0067\u006c\u0079 \u007b\u0070\u0075\u0062\u006c\u0069\u0063\u0020\u0020\u0020 \u0020\u0020\u0020\u0020\u0073\u0074\u0061\u0074\u0069\u0063 \u0076\u006f\u0069\u0064\u0020\u006d\u0061\u0069\u006e\u0028 \u0053\u0074\u0072\u0069\u006e\u0067\u005b\u005d\u0020\u0020 \u0020\u0020\u0020\u0020\u0061\u0072\u0067\u0073\u0029\u007b \u0053\u0079\u0073\u0074\u0065\u006d\u002e\u006f\u0075\u0074 \u002e\u0070\u0072\u0069\u006e\u0074\u006c\u006e\u0028\u0020 \u0022\u0048\u0065\u006c\u006c\u006f\u0020\u0077\u0022\u002b \u0022\u006f\u0072\u006c\u0064\u0022\u0029\u003b\u007d\u007d
(Šī programma izrādās vienkārša "Hello World" programma.)
Mīklas risinājumā viņi norāda uz šādu informāciju:
Nopietnāk šī mīkla kalpo, lai nostiprinātu iepriekšējo trīs mīklu mācības: Unicode escapes ir ļoti svarīgas, ja programmā nepieciešams ievietot rakstzīmes, kuras nav iespējams attēlot citādā veidā. Visos citos gadījumos izvairieties no tām.
Avots: [Java: Koda izpilde komentāros?!] (http://programming.guide/java/executing-code-in-comments.html)
\u000d izbeidz komentāru, jo \u escapes tiek vienādi konvertētas uz atbilstošajām Unicode rakstzīmēm pirms programma tiek tokenizēta. Komentāra sākšanai var izmantot arī \u0057\u0057 tā vietā, lai sāktu komentāru*.
Tā ir jūsu IDE kļūda, kurai vajadzētu izcelt rindu, lai būtu skaidrs, ka ar \u000d beidzas komentārs.
Tā ir arī valodas dizaina kļūda. Tagad to nevar izlabot, jo tas sabojātu programmas, kas no tās ir atkarīgas. \u escapes vai nu kompilatoram būtu jāpārvērš atbilstošajā Unicode rakstzīmē tikai tajos kontekstos, kur tam ir "jēga" (virknes literāli un identifikatori, un, iespējams, nekur citur), vai arī bija jāaizliedz ģenerēt rakstzīmes U+0000-007F diapazonā, vai arī abas. Jebkura no šīm semantikām novērstu to, ka komentārs tiek pabeigts ar \u000d, neiejaucoties gadījumos, kad \u ir lietderīgi - ņemiet vērā, ka tas *ietver arī \u izmantošanu komentāru iekšienē kā veidu, kā kodēt komentārus nelatīņu rakstībā, jo teksta redaktors var plašāk nekā kompilators saprast, kur \u ir nozīmīgi. (Tomēr es nezinu nevienu redaktoru vai IDE, kas parādītu \u escapes kā atbilstošas rakstzīmes jebkurā kontekstā.)
Līdzīga dizaina kļūda ir arī C ģimenē,1, kur backslash-newline tiek apstrādāts pirms komentāru robežu noteikšanas, tāpēc, piem.
// this is a comment \
this is still in the comment!Es to pieminēju, lai ilustrētu, ka ir viegli pieļaut šo konkrēto projektēšanas kļūdu un neapzināties, ka tā ir kļūda, kamēr nav par vēlu to labot, ja esat pieraduši domāt par tokenizāciju un parsēšanu tā, kā par tokenizāciju un parsēšanu domā kompilatoru programmētāji. Būtībā, ja jūs jau esat definējis savu formālo gramatiku un tad kāds izdomā sintaktisku īpašo gadījumu &;mdash; trigrafi, backslash-newline, patvaļīgu Unicode rakstzīmju kodēšana avota failos, kas ierobežoti ar ASCII, jebko citu &;mdash;, kas ir jāievieto, ir vienkāršāk pievienot transformācijas caurlaidi paredzot tokenizatoru, nekā pārdefinēt tokenizatoru, lai pievērstu uzmanību tam, kur ir jēga izmantot šo īpašo gadījumu.
1 Pedantiem: Es apzinos, ka šis C valodas aspekts bija simtprocentīgi iecerēts ar pamatojumu, — es to neizdomāju — ka tas ļautu mehāniski piespiedu kārtā uz perforētām kartītēm ievietot kodu ar patvaļīgi garām rindām. Tas joprojām bija nepareizs dizaina lēmums.
Es piekrītu @zwol, ka tā ir dizaina kļūda; bet es esmu vēl kritiskāks pret to.
\u evakuācija ir noderīga virkņu un rakstzīmju literālos rakstos; un tā ir vienīgā vieta, kur tai vajadzētu pastāvēt. Ar to būtu jārīkojas tāpat kā ar citiem izkļūšanas burtiem, piemēram, \n; un "\u000A" *vajadzētu nozīmēt tieši "\n".
Komentāros nav nekādas jēgas lietot \uxxxx - to neviens nevar izlasīt.
Tāpat nav jēgas lietot \uxxxx arī citās programmas daļās. Vienīgais izņēmums, iespējams, ir publiskās API lietojumprogrammās, kurās piespiedu kārtā ir jāiekļauj daži neascii burti - kad mēs to pēdējo reizi esam redzējuši?
Izstrādātājiem 1995. gadā bija savi iemesli, bet 20 gadus vēlāk šī izvēle šķiet nepareiza.
(jautājums lasītājiem - kāpēc šis jautājums arvien saņem jaunus balsojumus? vai šis jautājums ir piesaistīts no kādas populāras vietas?)