線形回帰とロジスティック回帰の違いは何ですか?
categorical](https://en.wikipedia.org/wiki/Categorical_variable)(または離散的)な結果の値を予測しなければならない場合、[ロジスティック回帰](https://en.wikipedia.org/wiki/Logistic_regression)を使用します。入力値を与えて結果の値を予測する場合にも[線形回帰](https://en.wikipedia.org/wiki/Linear_regression)を使うと思います。
では、この2つの方法論の違いは何でしょうか?
-
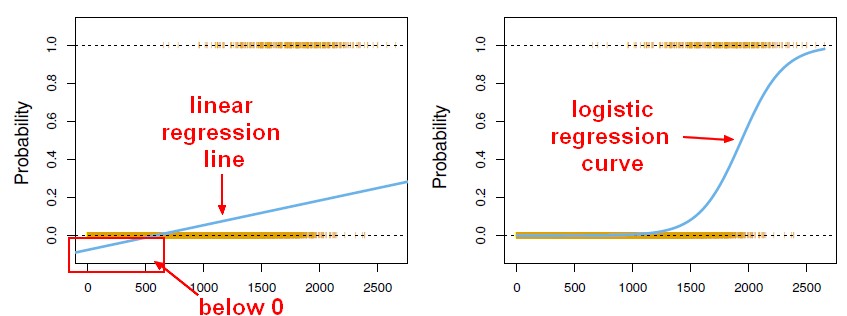
確率としての線形回帰の出力。
線形回帰の出力を確率として使いたくなりますが、それは間違いです。なぜなら、出力は負の値や1以上の値をとることができますが、確率はとることができないからです。線形回帰では実際に 回帰は実際には0より小さく、あるいは1より大きい確率を生成するかもしれないので 1よりも大きい確率が得られる可能性があるとして、ロジスティック回帰が導入されました。
出典: http://gerardnico.com/wiki/data_mining/simple_logistic_regression
[![enter image description here][1]][1].
-
成果について
線形回帰では、結果(従属変数)は連続的です。 無限にある可能性のある値のいずれかを持つことができます。
ロジスティック回帰では、結果(従属変数)は限られた数の可能な値しか持たない。
- 従属変数について
ロジスティック回帰は、応答変数がカテゴリー的な性質を持つ場合に使用されます。例えば、yes/no、true/false、red/green/blueなどです。 1位/2位/3位/4位など。
線形回帰は、応答変数が連続的な場合に使用されます。例えば、体重、身長、時間数などです。
-
計算式**)
線形回帰では、Y = mX + Cという形の方程式が得られます。 は次数1の方程式を意味します。
しかし、ロジスティック回帰では、次のような式が得られます。 Y = eX + e-X
-
係数の解釈**。
線形回帰では、独立変数の係数の解釈は非常に簡単です(つまり、他のすべての変数を一定にして、この変数が1単位増加すると、従属変数はxxxだけ増加/減少すると予想される)。
しかし、ロジスティック回帰では、ファミリー(二項、ポアソン。 など)やリンク(log、logit、inverse-logなど)によって、解釈が異なります。
-
エラー最小化手法
線形回帰では、通常の最小二乗法を用いて誤差を最小化し 誤差を最小にして最良の適合性を得るために使用し、ロジスティック回帰では は最尤法を用いて解を求める。
線形回帰は通常、データに対するモデルの最小二乗誤差を最小化することで解かれ、したがって大きな誤差は二次的にペナルティを受けます。
ロジスティック回帰はその逆です。ロジスティック損失関数を使用すると、大きな誤差は漸近的に一定のペナルティを受けます。
これがなぜ問題なのか、カテゴリー的な{0, 1}の結果に対する線形回帰を考えてみましょう。モデルが結果を38と予測し、実際には1だった場合、あなたは何も失っていません。線形回帰はその38を減らそうとしますが、ロジスティックはそうはしません(同じくらい)2。

線形回帰では、結果(従属変数)は連続的です。無限の可能性を持つ値のいずれかを持つことができます。ロジスティック回帰では,結果(従属変数)は限られた数の可能な値しか持たない.
例えば、Xが家の面積(平方フィート)を含み、Yがそれらの家の販売価格を含む場合、線形回帰を使用して家のサイズの関数として販売価格を予測することができます。可能な販売価格は実際には任意ではないかもしれませんが、線形回帰モデルが選択されるほど多くの可能な値があります。
代わりに、家の大きさに基づいて、家が20万ドル以上で売れるかどうかを予測したい場合は、ロジスティック回帰を使用します。可能な出力は、「はい、その家は20万ドル以上で売れる」、「いいえ、その家は売れない」のいずれかです。
簡単に言えば、線形回帰は、連続した無限の可能性のある値を出力する回帰アルゴリズムであり、ロジスティック回帰は、入力があるラベル(0または1)に属する 'probability'を出力する二値分類アルゴリズムと考えられます。