선형 회귀 및 는 어떤 차이가 로지스틱 회귀?
값을 예측할 때 우리는 [범주] (https://en.wikipedia.org/wiki/Categorical_variable) (또는 이산식) 우리가 사용하는 결과를 [로지스틱 회귀] (https://en.wikipedia.org/wiki/Logistic_regression). I believe 우리가 사용하는 [선형 회귀] (https://en.wikipedia.org/wiki/Linear_regression) 의 값을 예측할 수 있는 점을 고려할 때 입력 값을 결과물일 따름이다.
그런 다음 두 가지 방법을 차이가 뭘까?
선형 회귀 출력할 충분히 -
39 의 그냥 구미만 당긴다고 it& 사용할 수 있지만 충분히 it& # 39 의 선형 회귀 출력할 수 있기 때문에 실수를 할 수 없는 반면, 1 보다 큰 출력 확률 및 제외어 회귀 지정값이 실제로 있다.
충분히 생산할 수 있는 보다 큰 0 보다 작은, 심지어 1, 로지스틱 회귀 도입되었다.
출처: http://gerardnico.com/wiki/data_mining/simple_logistic_regression
! [입력하십시오. 이미지 여기에 설명을] [1] 그 -
선형 회귀 (종속 변수) 의 결과를) 가. 무수한 가능한 값 중 하나를 가질 수 있습니다.
로지스틱 회귀 (종속 변수) 만 있는, 결과에 대한 제한된 수의 가능한 값.
종속 변수 -
로지스틱 회귀 응답 특성을 가진 범주 가변입니다 경우에 사용됩니다. 예를 들어 yes / no, 참 / 거짓, 파랑, 녹색 / 적색 / 1st/2nd/3rd/4th, etc.
답글을 때 사용되는 선형 회귀 가변입니다 횡단면도. 예를 들어, 무게, 높이, 시간, etc.
방정식입니다 -
선형 회귀 원하는거요 방정식입니다 형태의 기울기는 Y = mX + C 함께 고말은 방정식입니다 도 1.
그러나 이는 기울기는 방정식입니다 형태의 로지스틱 회귀 Y = e< sup> X< /sup>;;; + e< X< /sup> sup> -;;;
-
-
- 계수 해석
-
독립 변수는 계수 선형 회귀, 에 대한 해석은 매우 쉽습니다 (즉, 모두 갖고 다른 com/go/4e6b330a_kr 상수입니다 함께 유닛 증가 / 감소, 이 변수는 종속 변수 xxx 로 늘어날 것으로 보인다).
하지만 로지스틱 회귀 (맑음, 포아송 가족요 따라 달라집니다. 등) 와 링크 (log 를 로짓, 보색으로 로그에서는 등) 를 사용하는 다른 해석도 있다.
오류를 최소화 기법은 -
선형 회귀 ordinary squares 최소화하도록 이상 사용하는 방법 한 동안 도착하면 오류 및 최상의 선택인지 로지스틱 회귀 이 솔루션을 사용하는 방법을 maximum likelihood 도착할 예정이다.
선형 회귀 모델을 분류인 최소제곱 최소화할 수 있어 큰 오류는 오류가 데이터를 받는 정방형으로.
로지스틱 회귀 () 는 그 반대입니다. 로지스틱 함수를 사용하여 오류뿐만 받는 것으로 인해 큰 손실을 충족되었으며 점근 상수입니다.
이유를 알 수 있는 범주 {0, 1} 이 선형 회귀 결과를 고려해보십시오 문제가 있다. 결과는 예측 모델의 경우, 1, # 39 이것은 you& 때 38, ve 손실됩니다 아무것도아니야. # 39, 38, 로지스틱 wouldn& 줄일 수 있는 선형 회귀 시도할 것이라고 밝혔다. 2 t (많이) < < /sup> sup>;;).

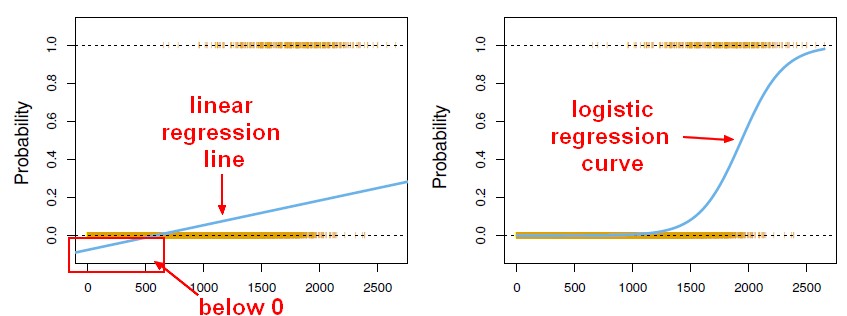
선형 회귀 (종속 변수) 의 결과를) 가. 무수한 가능한 값 중 하나를 가질 수 있습니다. 로지스틱 회귀 (종속 변수) 만 있는, 결과에 대한 제한된 수의 가능한 값.
예를 들어, X, Y map_layer 해당 영역을 map_layer 평방 피트 (주택 판매 단가가 그 집 크기를 예측할 수 있는 함수로 집이었 판매 가격을 선형 회귀 사용할 수 있습니다. 이 될 수 없는 동안 가능한 selling price , 모든 가능한 값 너무 많아 선형 회귀 모델을 선택한 것이 될 수 있다.
대신 예측, 하고 싶은 경우, 달러 이상의 크기를 기준으로 서버인지에 집이었 200K, 로지스틱 회귀를 사용하는 것과 판매할 수 있을 것 "이라고 말했다. 네, 집에 가지 가능한 출력입니다 이상 판매할 예정이며, 또는 어떤 집을 $200K 않습니다.
바로 전날 추가 분입니다.
-
- 선형 회귀
인정해온 문제를 해결하기 위해 특정 요소에 출력 값을 추정하는 예측 / X (말하도다 f (x)). 긍정적인 결과를 예측할 수 있는 함수 또는 음의 값을 는 코티노우스 수 있습니다. 이 경우 일반적으로 입력 및 출력 값을 가지고 많은 데이터세트를 참조용이므로 각 그 희망이었네 목표는 이 데이터 세트 모델을 잘 할 수 있도록 새로운 요소를 다른 / 본 적이 있다고 보고 출력입니다 수 있다. 다음은 피팅이면 점 설정할 수 있지만, 일반적으로 고전적인 예로 선 선형 회귀 모델을 사용하여 높은 다항식 도) 보다 복잡한 맞게 사용할 수 있습니다.
- 문제 해결 *
두 가지 방법으로 해결할 수 회귀 중 하나이다.
- 보통 방정식입니다 (직접판매용 방식으로 문제를 해결하기 위해)
- 경사 하강법 (반복적인 외곽진입)
-
- 로지스틱 회귀
주어진 문제를 해결하기 위해 인정해온 분류 N 같은 분류 할 수 있는 요소를 범주입니다. 예를 들어 일반적인 예로는, 스팸 메일 분류할 수 있는 만큼 이를 방관하겠나 찾기를 느릅 나무 또는 주어진 차량 (자동차, 트럭, 부가가치통신망 (van), etc.) 이 범주에 속한다. # 39 의 유한 집합, s 는 기본적으로 that& 출력물에는 데크레티 값.
- 문제 해결 *
로지스틱 회귀 문제가 해결될 수 사용해서만 그래디언트 혈통이다. 일반적으로 선형 회귀 유일한 차이점은 현세생 작용한 매우 비슷하지만 서로 다른 가설이 있다. 선형 회귀 양식 있는 가설이 있다.
h(x) = theta_0 + theta_1*x_1 + theta_2*x_2 .. 여기서 우리는 맞춤, 세타 (θ) 는 모델을 시도하고 있다. [1, x_1, x_2.] 는 입력 벡터. 로지스틱 회귀 가설이 함수은 다르다.
g(x) = 1 / (1 + e^-x)이 좋은 기능이 기본적으로 모든 가치를 위한 적절한 속성, it 매핑하므로 처리할 수 있는 범위 [0.1] 중 프로파바빌레티스 클라시피카틴. 예를 들어 이런 이진 분류에서 g (X) (positive class probability 속하는 것으로 해석될 수도 있다. 이 경우 일반적으로 서로 다른 클래스 있습니다 어떤 결정을 통해 분판된 않는비즈니스 분판의 결정하는 사이의 경계 조건이 커브를 등급이. 다음 예는 데이터세트를 분판된 두 개의 클래스가 있습니다.
기본 차이:
즉 a 는 선형 회귀 모델을 기본적으로 회귀 부여하느뇨 비사양 별도형 / 횡단면도 출력을 지원한다. 그래서 이 외곽진입 보기입니다 값입니다. 예를 들면 다음과 같습니다. 지정된 x 지정하십시오. f (x)
예를 들어 부동산 가격이 다른 주어진 훈련 집합 제거율과 훈련이 끝나면 부동산 가격 인상 요인이 될 결정하는 데 필요한 제공할 수 있습니다.
로지스틱 회귀 기본적으로 이진 분류에서 즉 알고리즘입니다 별도형 함수에 대한 중요한 출력입니다 여기 있을 수 있다. 예를 들면 다음과 같습니다. 만약 주어진 x f (x), 다른 분류 할 수 있도록 > 하한계 분류하고 1 0.
예를 들어 일정한 크기로 뇌 종양 크기를 훈련 데이터 집합을 입력으로 베니니 악성 종양 또는 해당 a 여부를 확인하기 위해 사용할 수 있습니다. 따라서 이 별도형 인컨텍스트 출력이 0 또는 1.
- 이 기능은 기본적으로 가설 함수
간단히 말해, 선형 회귀 () 는 회귀 알고리즘입니다 우스푸스 연속, 무한 가치, 할 수 있는 & # 39 는 이진 분류, 즉 로지스틱 회귀 고려되는지 비호환성의 알고리즘입니다 출력입니다 probability& # 39;; 입력 속한 레이블 (0 또는 1).
| Basis | Linear | Logistic |
|-----------------------------------------------------------------|--------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------|
| Basic | The data is modelled using a straight line. | The probability of some obtained event is represented as a linear function of a combination of predictor variables. |
| Linear relationship between dependent and independent variables | Is required | Not required |
| The independent variable | Could be correlated with each other. (Specially in multiple linear regression) | Should not be correlated with each other (no multicollinearity exist). |한 마디로. 선형 회귀 보기입니다 횡단면도 출력입니다. 즉, 임의의 값으로 범위 사이의 값. 로지스틱 회귀 보기입니다 이산식 출력입니다. 예를 들어 Yes / No, 0/1 종류의 출력입니다.
위의 설명을 통해 더 나은 동의할 수 없다. 그 위에 같은 몇 가지 더 유사하다.
일반적으로 선형 회귀, 잔차 분산 있는 것으로 간주됩니다. 로지스틱 회귀 잔차 분산 독립화할 정상적으로 할 수는 없습니다.
선형 회귀 설명 변수 값을 얻을 수 있는 경우를 일정한 변화가 변화가 상수입니다 응답 변수. 이러한 가정에 보유하지 응답 변수 값을 경우 제이보드 확률 (로지스틱 회귀)
GLM (일반화 선형 모델) 사이의 관계는 선형이라는 독립변수와 종속변수 solaris. 않습니다. 그러나 가정 및 독립 변수 사이의 관계는 선형이라는 https://partner. 함수은 로짓 모델.
로지스틱 회귀 () 가 유일하게 선형 회귀 결과를 있는 반면, 결과에 대한 제한된 수의 가능한 값 (이산식).
예: 시나리오에서는, 주어진 값 x 는 y ie 속도는 그 크기를 예측하는 플롯할 평방 피트 아래에 완료되니라 플롯할 선형 회귀.
하고 싶은 경우, 대신 크기를 기준으로, 예측, Rs, 로지스틱 회귀를 사용하는 것과 300000 플롯할 나열할지 이상 판매할 수 있을 것 "이라고 말했다. 예, 300000 이상 가지 가능한 출력입니다 플롯할 통해 판매됩니까 Rs 또는 아닙니다.
간단히 말해서, 선형 회귀 모델을 더욱 멀리 떨어져 있는 경우에는 테스트 케이스 도착 하한계 (말하도다 = 0.5) 를 y y = 0 = 1 이고 것이다. 그럼 되며 이 경우 가설 바뀔 것이라고 한다. 따라서 선형 회귀 모델을 데사용됩니다 분류 문제가 아니다.
또 다른 문제는 y = 0, h, y = (x) 의 분류는 경우 1 > 수 있습니다. 1 개 또는 <. 우리가 사용하는 0.so 0< = h (x) = 1, 로지스틱 회귀, < 있었다.
로지스틱 회귀 사용되는 것으로 같은 범주 출력입니다 Yes / No, 낮은 / 중간 / 높은 상술합니다. 당신은 기본적으로 두 가지 유형의 로지스틱 회귀 이진 로지스틱 회귀 (예 / 아니오, 승인됩니다 / 승인 불가) 또는 멀티 클래스 로지스틱 회귀 (낮음입니다 / 보통 / 높은 자리) 에서 0-9 등)
반면, 종속 변수 (y) 는 선형 회귀 경우) 가. y = mx + c 가 단순 선형 회귀 방정식입니다 (m = 기울기, c 는 y 절편). 1 개 이상의 독립 변수 (x1, x2, x3.) 는 멀티링어 회귀 등)
변수 x, y 는 선형 회귀 고말은 연속되도록 일괄이라는 관계가 없음을 의미한다. 수 년간 연봉 에서 emailxtender = 시도할 것이라는 전망이 나오고 있다. 이제 연봉은 독립 변수 (y), (x) 는 년 경력을 종속 변수.
- y = b0+ 1*x1 ! [선형 회귀] [1] 우리는 항상 최적의 값을 찾는 b0 와 b1 선 단축시킵니다 관측 데이터를 있는 미국 최고의 피팅이면 부여하느뇨. 이것은 매우 큰 값을 줄 수 있는 가치를 방정식입니다 연속되도록 x = 0. 이 라인은 호출됨 선형 회귀 모델을.
로지스틱 회귀 () 는 유형의 분류 기법. 의해 용어가 잘못 오더할 시장을 의미한다. 여기서는 표시할지를 y = 0 또는 1 있다.
여기서 p (y = 1) 먼저 찾아야 할 때 (우프로바빌레티 y = 1) 에서 x 포무일 같습니다.
P 가 y 아래에 포무일 프로바이빌레티 관련이 있다.
우리는 기회를 갖는 내말들어봐 emailxtender = 1 로 분류 및 종양 때문에 암 종양 50% 이상 받을 가능성이 있기 때문에 암 50% 미만 0 으로. ! [5] [4]
여기서 0 으로 빨강입니다 시점이 되며 녹색 점 1 로 반면 것으로 예상 됩니다.