Care este diferența între UTF-8 si ISO-8859-1?
Care este diferența între UTF-8 și ISO-8859-1?





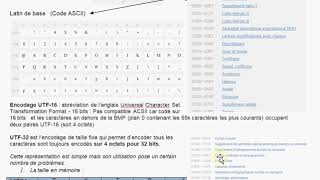










UTF-8 este un multibyte codare care poate reprezenta orice caracter Unicode. ISO 8859-1 este un singur octet de codare care pot reprezenta primele 256 de caractere Unicode. Atât codarea ASCII exact în același mod.
Wikipedia explică destul de bine: UTF-8 vs Latin-1 (ISO-8859-1). Prima este o lungime variabilă de codare, acesta singur octet de lungime fixă de codare. Latin-1 codifică doar primele 256 de puncte de cod din setul de caractere Unicode, întrucât UTF-8 poate fi folosit pentru a codifica toate punctele de cod. La fizică codare nivel, doar puncte de cod 0 - 127 obține codificate identic; puncte de cod 128 - 255 diferă de a deveni 2-secvență de octet cu UTF-8 întrucât ele sunt singur bytes cu Latin-1.
UTF
UTF este o familie de multi-octet de scheme de codare care pot reprezenta Unicode cod de puncte care pot fi reperesentative de până la 2^31 [aproximativ 2 miliarde de euro] caractere. UTF-8 este un flexibil sistem de codificare care utilizează între 1 și 4 bytes pentru a reprezenta primele 2^21 [aproximativ 2 milioane de puncte de cod.
Povestea pe scurt: orice caracter, cu un punct de cod/de ordine reprezentarea de mai jos 127, aka 7-bit-în condiții de siguranță ASCII este reprezentat de aceeași 1-secvență de octet ca cele mai multe alte single-byte codificări. Orice personaj cu un punct de cod de mai sus 127 este reprezentat de o succesiune de două sau mai multe bytes, cu special de codare explicat cel mai bine aici.
ISO-8859
ISO-8859 este o familie de un singur octet de scheme de codare folosit pentru a reprezenta litere, care pot fi reprezentate în gama de 127 255. Aceste diverse alfabete sunt definite ca "piese" în formatul ISO-8859-n, cele mai cunoscute dintre acestea fiind probabil ISO-8859-1 aka 'latină-1'. Ca cu UTF-8, 7-bit-în condiții de siguranță ASCII rămâne neschimbat indiferent de codare familia.
Dezavantajul la acest sistem de codificare este incapacitatea sa de a găzdui limbi format din mai mult de 128 de simboluri, sau în condiții de siguranță pentru a afișa mai mult de o familie de simboluri la un moment dat. La fel de bine, ISO-8859 codificări au căzut din favoarea cu creșterea de UTF. ISO "Grup de Lucru" responsabil de ea au desființat în 2004, lăsând de întreținere, de la părintele său subcomisiei.
ISO-8859-1 este o moștenire standarde din nou în 1980. Acesta poate reprezenta doar 256 de caractere atât de potrivite numai pentru anumite limbi în lumea occidentală. Chiar și pentru multe limbi suportate, unele personaje sunt lipsă. Dacă creați un fișier text în această codificare și încercați să copiați/lipiți unele caractere Chinezești, veți vedea rezultate ciudate. Deci, cu alte cuvinte, don't-l folosească. Unicode a preluat în lume, și UTF-8 este destul de mult de standardele în aceste zile doar daca nu ai moștenire motive (cum ar fi anteturile HTTP care trebuie să compatibil cu totul).
-
ASCII: 7 biți. 128 codul puncte.
-
ISO-8859-1: 8 biți. 256 cod puncte.
-
UTF-8: 8-32 biți (1-4 bytes). 1,112,064 puncte de cod.
Ambele ISO-8859-1 sau UTF-8 sunt compatibil cu ASCII, dar UTF-8 nu este compatibil cu ISO-8859-1:
#!/usr/bin/env python3
c = chr(0xa9)
print(c)
print(c.encode('utf-8'))
print(c.encode('iso-8859-1'))Ieșire:
©
b'\xc2\xa9'
b'\xa9'Dintr-o altă perspectivă, fișierele care ambele unicode și ascii codificări nu reușesc să citească, deoarece acestea au un octet 0xc0 în ele, par să se citească de către iso-8859-1 în mod corespunzător. Avertismentul este că dosarul ar trebui't au caractere unicode în ea, desigur.
Motivul pentru care cercetarea la această întrebare a fost de perspectiva, este în ce mod sunt ele compatibile. Latin1 charset (iso-8859) este 100% compatibil pentru a fi stocate într-un utf8 datastore. Toate ascii & extins-ascii caractere vor fi stocate ca un singur octet.
Mergând în sens invers, de la utf8 să Latin1 charset poate sau nu poate lucra. Dacă există 2-byte de caractere (caractere dincolo extins-ascii 255) nu se vor depozita într-un Latin1 datastore.